

What is structured data vs unstructured data? Structured data utilizes a predefined tabular schema neatly organized into rows, columns, and strictly typed fields that you can query via SQL. Unstructured data lacks a fixed format. It consists of raw files, text, and media requiring parsing, metadata, or machine learning models to analyze. Semi-structured data bridges this gap by using flexible tags and nested hierarchies like JSON.
In my work building data platforms, the goal is no longer choosing one format over another. It is making all three formats queryable, governable, and AI-ready within a unified stack. Today, 74% of enterprises manage more than 5PB of unstructured data, yet less than 1% of it actually fuels generative AI systems.
Modern production systems rely on a structured core, unstructured enrichment, and semi-structured flexibility. Do not force a binary choice.
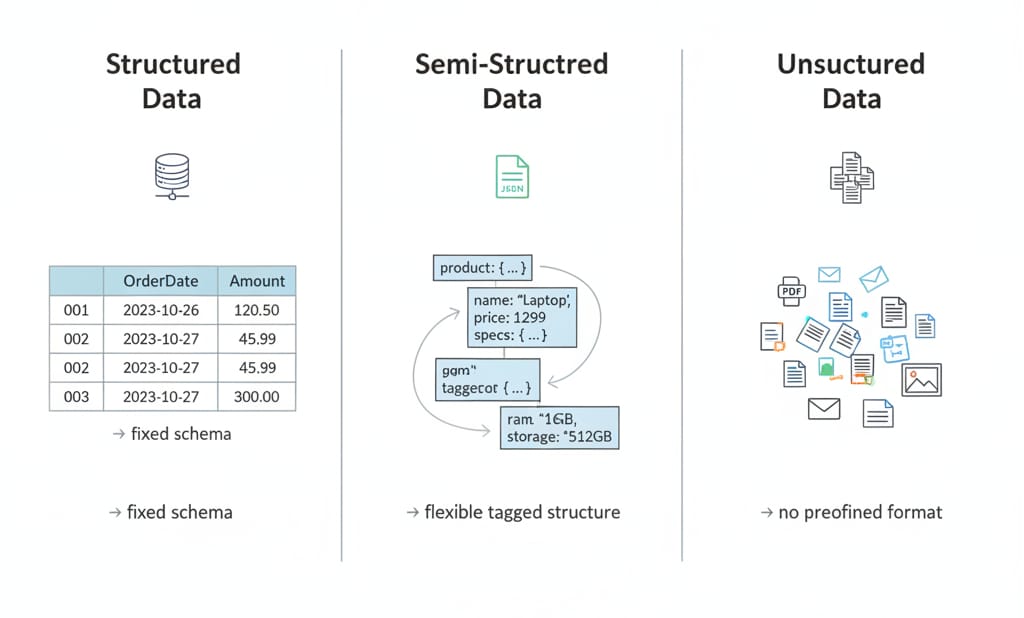
What Is the Difference Between Structured and Unstructured Data?
The core difference between structured and unstructured data dictates how machines read and enforce schemas. Structured data enforces schema-on-write, rejecting inputs that break predefined rules. Unstructured data uses schema-on-read, storing raw payloads and forcing the processing engine to interpret meaning at query time.
Structured vs Unstructured Data Comparison Table
| Feature | Structured Data | Semi-Structured Data | Unstructured Data |
|---|---|---|---|
| Schema | Schema-on-write (rigid) | Schema-on-read (flexible) | No predefined tabular schema |
| Storage | Relational DBs, Data warehouses | Document DBs, Object storage | Data lakes, Object storage |
| Query method | SQL | NoSQL, JSONPath | Vector search, full-text search |
| Flexibility | Low | Medium | High |
| Governance | Low difficulty (field-level controls) | Medium difficulty | High difficulty (document-level) |
| Processing cost | Low (pre-computed constraints) | Medium (parsing overhead) | High (requires NLP, OCR, embeddings) |
| AI readiness | High (ready for tabular ML) | High (easily flattened) | Low (requires preprocessing) |
| Best fit | Financial reporting, strict joins | Event streaming, evolving APIs | Sentiment analysis, RAG pipelines |
Choose data types based on how much structural constraint you need to impose for your specific processing task.
Structured Data Definition, Examples, and Where It Works Best
Structured data definition
Structured data is schema-based information stored in rigid fields with explicitly defined data types (integers, strings, dates). It lives primarily in relational databases and typed data warehouses.
Structured data examples
- Customer records (Name, ID, Region)
- Financial transaction logs
- Inventory counts
- Timestamped product usage events
Where I use structured data
Structured formats excel when mathematical precision is non-negotiable. I rely on them for multi-table joins, aggregations, financial reporting, ACID-compliant transactions, and tabular machine learning features.
Structured systems reject payloads that violate the predefined schema. This guarantees predictable queries and high-speed indexing.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
subscription_tier VARCHAR(50) NOT NULL,
join_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Use structured data when query patterns are highly predictable and analytical consistency is your primary requirement.
Unstructured Data Definition, Examples, and Why It Is Harder to Analyze
Unstructured data definition
Unstructured data encompasses any payload lacking a fixed tabular schema. It relies on file-level storage and requires external interpretation to become programmatically useful.
Unstructured data examples
- Free-form support ticket text
- Customer call transcripts
- Vendor PDF invoices
- Public web pages and competitor pricing documents
Why unstructured data is difficult to analyse
Traditional query languages require predefined columns. Unstructured files present inconsistent formats, weak metadata, ambiguous natural language, and multimodal content (text mixed with images). You cannot run a mathematical GROUP BY operation on a folder of PDFs.
I never use unstructured data completely raw. Unlocking its value requires metadata for discoverability, parsing for machine readability, and vector embeddings for semantic search.
Unstructured data is computationally expensive to use. You must build extraction pipelines to transform raw files into machine-readable assets.
Types of Data in Databases: The Structure Spectrum
In production, the structured vs unstructured binary falls apart. I evaluate data along a five-step spectrum:
- Rigidly structured: Relational tables with strict constraints (PostgreSQL).
- Flexibly structured: Wide event tables with optional columns (Parquet).
- Semi-structured: Hierarchical payloads with nested fields and evolving keys (JSON).
- Lightly structured: Raw content wrapped in standardized metadata (Emails with rigid headers but free-text bodies).
- Truly unstructured: Raw, unannotated binary files (MP4 video).
Is JSON structured or unstructured data?
JSON is semi-structured data. It utilizes distinct keys and hierarchies, making it highly queryable, but its schema varies rapidly without breaking the ingestion pipeline.
Categorizing edge cases
- CSV: Structured, but weakly typed (often treated as strings until parsed).
- XML: Semi-structured.
- Emails: Lightly structured.
- Logs: Semi-structured.
Use the spectrum to decide how much structure to enforce at ingestion, rather than forcing everything into strict tables immediately.
How Structured and Unstructured Data Are Stored
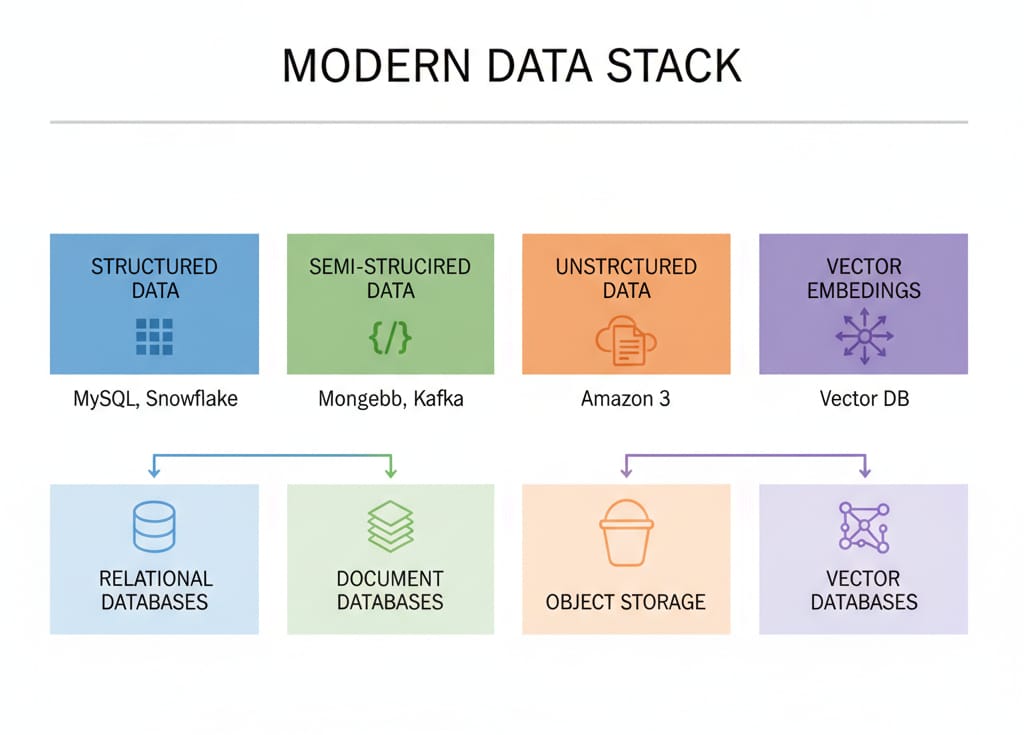
How structured data is stored
It lives in relational databases (MySQL), traditional data warehouses (Snowflake), and lakehouse tables. These engines utilize B-tree indexes and columnar storage for read-heavy analytics.
How semi-structured data is stored
It thrives in document databases (MongoDB), event streaming platforms (Kafka), and open table formats (Apache Iceberg) utilizing nested arrays.
How unstructured data is stored
It resides in highly scalable, low-cost object storage (Amazon S3), distributed file systems, and raw data lakes.
Where vector databases fit
Vector databases store and search high-dimensional embeddings: numeric representations of unstructured data. Adoption of vector databases grew 377% year over year in Databricks' 2024 State of Data + AI report. However, they do not replace relational databases. I use them exclusively for semantic retrieval, mapping vectors back to a canonical source of truth stored in PostgreSQL or S3.
The old "warehouse for structured, lake for unstructured" model is obsolete. Modern open table formats allow high-performance SQL directly over object storage.
How Modern AI Systems Use Both Data Types
Generative AI increases the value of structured data. Building applications solely on unstructured documents frequently causes hallucinations. The winning architectural pattern is a structured core enriched by unstructured context.
The RAG Architecture
Retrieval-Augmented Generation (RAG) utilizes both ends of the data spectrum. When designing an AI copilot, I structure the pipeline this way:
- The system executes a SQL query to filter structured metadata (example:
WHERE customer_id = 123). - It runs a vector search to retrieve semantically relevant unstructured document chunks.
- The LLM joins these verified facts to generate a grounded, accurate response.
Never rely on vector search alone. Ground your AI applications using structured metadata to ensure deterministic accuracy.
Structured vs Unstructured Data in Machine Learning
The format strictly dictates the machine learning approach:
- Tabular ML (Structured): Algorithms like XGBoost predict outcomes based on exact feature columns (predicting user churn based on login counts).
- Deep Learning (Unstructured): Transformers and CNNs parse natural language and pixels.
To feed unstructured text into algorithms, I use embeddings. This process maps words into continuous numeric arrays, creating a machine-searchable semantic representation.
In big data systems like Apache Spark, workloads mix streaming JSON logs, daily CSV dumps, and distributed NLP. Spark unifies these via DataFrames, projecting flexible schemas over distributed object storage.
Machine learning success depends entirely on how accurately you normalize and label the underlying data inputs.
Can Unstructured Data Be Converted to Structured Data?
Yes. I routinely convert unstructured inputs into structured outputs using multi-step extraction pipelines.
The standard conversion workflow:
- Ingest and classify: Detect source type and assign baseline metadata.
- Parse and extract: Deploy Optical Character Recognition (OCR) for scans and LLMs to pull specific entities from raw text.
- Normalize and validate: Map extracted outputs to a strict JSON schema.
- Index and monitor: Store the canonical record and monitor extraction confidence scores.
import json
from extraction_lib import LLM_Extractor
raw_ticket = "Hey, I am using the Pro plan on account #4421. The billing dashboard keeps crashing."
schema = {
"category": "string",
"feature": "string",
"account_id": "integer",
"urgency": "string"
}
structured_output = LLM_Extractor.extract(text=raw_ticket, target_schema=schema)
print(json.dumps(structured_output, indent=2))When extracting data from the public web, I avoid brittle custom scrapers. Instead, I rely on purpose-built extraction APIs that crawl, parse, and normalize messy HTML into deterministic JSON at scale.
Conversion reliability depends entirely on strict target schema design and aggressive validation rules.
Decision Matrix: Choosing the Right Database
Start with your query pattern, not your file type. Ask:
- Do I need ACID transactions?
- Does the schema evolve daily?
- Am I querying by exact match or semantic proximity?
| Tool Type | Best For | Avoid When | Query Style |
|---|---|---|---|
| Relational Database | Core state, financial data, joins | Highly variable schemas | Exact (SQL) |
| Document Database | Rapid prototyping, JSON logs | Complex multi-table joins | Key/Value, JSONPath |
| Object Storage | Archiving raw unstructured files | Sub-second transactional reads | File retrieval |
| Lakehouse | Unified analytics over mixed data | Single-node transactional apps | SQL over files |
| Vector Database | Semantic search, RAG | Canonical source of truth | Proximity/Distance |
Stack architecture depends on query velocity and schema volatility.
Governance, Cost, and Dark Data
What percentage of data is unstructured?
Approximately 78% of all enterprise data stored is unstructured.
Because it lacks standardized metadata, unstructured data frequently devolves into "dark data," meaning it is retained for compliance but never utilized.
The governance divide
I apply field-level access controls and dynamic column masking to structured data easily. Governing unstructured data is much blunter. Detecting personally identifiable information (PII) inside a 50-page PDF requires proactive NLP scanning before the file ever hits a shared bucket.
The AI-readiness gap
Storage is cheap, but preprocessing is expensive. The real cost shifts to OCR licensing, NLP extraction, and embedding generation. Consequently, less than 1% of enterprise unstructured data is actually used in generative AI today.
Hoarding raw files does not equal AI readiness. You must invest in automated classification and metadata tagging.
The Practical Rule for 2026 Data Stacks
When architecting a new data pipeline, I follow four strict principles:
- Base infrastructure on the query pattern.
- Accommodate schema volatility.
- Align with governance constraints (field-level vs document-level).
- Optimize for processing cost, not just storage cost.
Stop separating structured and unstructured data into isolated silos. Build unified systems that make both types queryable and AI-ready simultaneously.
FAQ
What is the difference between structured and unstructured data?
Structured data uses a predefined tabular schema enabling fast SQL queries. Unstructured data lacks a fixed format, requiring extraction or machine learning to analyze.
What are examples of structured data?
Customer relationship management (CRM) fields, financial records, database tables, inventory rows, and timestamped product events.
What are examples of unstructured data?
Free-form text, PDFs, call transcripts, images, audio files, and raw web pages.
Is JSON structured or unstructured data?
JSON is semi-structured. It utilizes distinct keys and a clear hierarchy, but its schema can dynamically change between payloads.
Why is unstructured data difficult to analyse?
It suffers from inconsistent formats, weak metadata, and context ambiguity. Making it machine-readable requires expensive preprocessing.
What percentage of data is unstructured?
Approximately 78% of total stored enterprise data is unstructured.
Can unstructured data be converted to structured data?
Yes. You can convert it using an extraction pipeline that handles parsing, entity extraction, schema validation, and normalization into JSON or database tables.
