

Anthropic Claude Fable 5 is a 1-million-token context, 128,000-output frontier model built for long-horizon agentic workflows and complex document reasoning. It delivers the raw intelligence of the access-gated Claude Mythos 5, but wraps it in public-facing safeguards that reroute sensitive prompts to Claude Opus 4.8. At $10 per million input tokens, it is not a blanket default for everyday chat. It is a premium routing tier.
What is Claude Fable 5?
Claude Fable 5 is Anthropic's most capable generally available AI model. It features a 1M-token context window, up to 128K output tokens, and always-on adaptive thinking for complex reasoning. Because it enforces strict safety refusals and a 30-day data retention policy, teams should treat it as a specialized engine for difficult, high-value tasks rather than a default upgrade.
Quick-Spec Card
- Model ID:
claude-fable-5 - Context Window: 1,000,000 tokens
- Output Limit: 128,000 tokens
- Pricing: $10 input / $50 output (per MTok)
- Availability: Claude API, AWS Bedrock, Vertex AI, Microsoft Foundry
- Data Governance: Covered Model (30-day retention applies)
| Best Fit Workloads | Poor Fit Workloads |
|---|---|
| Long-horizon coding agents | Simple chat or summarization |
| Error-expensive document analysis | High-volume, low-margin generation |
| Multimodal reasoning over large context | Workflows requiring Zero Data Retention (ZDR) |
Before you switch defaults, shortlist three internal workloads you care about most. Use this guide to determine exactly where Fable 5 belongs in your production stack.
What Claude Fable 5 Actually Is
Fable 5 provides the underlying power of Anthropic's frontier Mythos model, packaged with necessary enterprise safeguards for general public deployment. Stop benchmarking against Mythos 5 unless you are part of a trusted-access program.
Claude Fable 5 vs Claude Mythos 5
Claude Fable 5 and Claude Mythos 5 share the identical underlying model. The difference is access and safety. Fable 5 is the public version equipped with safety classifiers that block and reroute high-risk queries. Mythos 5 has these safeguards lifted but is strictly access-gated for approved users in Project Glasswing.
Deploying frontier reasoning at scale introduces distinct cybersecurity and biological risks. Anthropic wrapped the base Mythos capability in Fable 5's visible safety classifiers to allow broad commercial access without violating responsible scaling policies.
Availability and Access Caveats
Fable 5 defaults to adaptive thinking. The model dictates its own reasoning depth based on your prompt's complexity. You can access it via the Claude API, Claude Platform on AWS, Amazon Bedrock, Vertex AI, and Microsoft Foundry.
Whether you utilize the API or access the model through designated Claude AI plans, always check the latest limits. Usage credits and Claude Max plan parameters change frequently, so verify your exact tier allocations before assuming unlimited capability.
Benchmarks: What the Scores Actually Mean
Fable 5 leads in long-horizon software engineering and multimodal analysis. However, treat public benchmarks as a starting point. Do not substitute vendor-reported scores for real-world pilot testing.
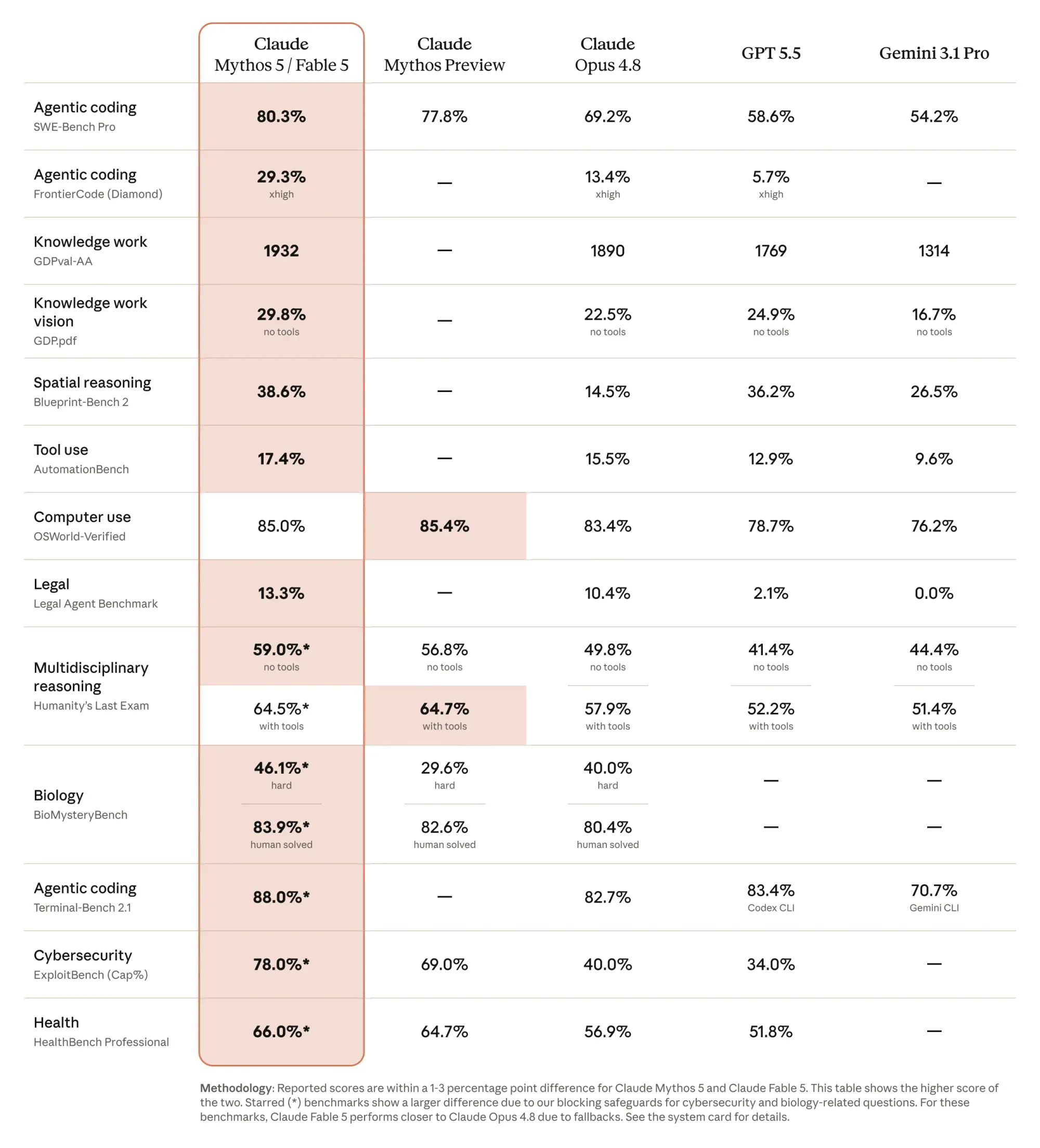
Anthropic highlights raw capability in its launch materials. Your production reality includes API latency, prompt constraints, and safety refusals.
Mandatory Benchmark Truth Table
| Benchmark Name | Capability Tested | Claude Fable 5 Result | Comparison Model | Practical Meaning | Deployment Caveat |
|---|---|---|---|---|---|
| SWE-Bench Pro | Agentic software engineering | 80.3% | Opus 4.8 (69.2%) | Resolves complex GitHub issues autonomously. | Effort parameter materially changes scores. |
| FrontierCode Diamond | Long-horizon coding | 29.3% | Opus 4.8 (13.4%) | Deep reasoning over massive repositories. | Highly dependent on context caching. |
| Multimodal DocQA | Vision & Document reasoning | Highest in class | Gemini 3.1 Pro | Extracts structured data from dense visual charts. | Check tokenizer inflation before modeling cost. |
| ProgramBench | Restricted domain coding | Omitted | Mythos 5 | Tests security-adjacent coding tasks. | Security prompts often trigger fallbacks. See Anthropic's refusals and fallback documentation. |
Coding and Knowledge Work
Fable 5's defining advantage is software engineering autonomy. It handles deeper context spans and requires fewer manual interventions than Opus 4.8. The 1M-token window excels at analyzing disparate, multimodal documents, holding context sharply across hundreds of pages of legal text.
Independent Signals vs. Demos
Formal metrics prove baseline competence. Launch demos—like highly optimized agent runs—represent partner-guided implementations, not out-of-the-box API guarantees. Third-party evaluations explicitly warn against quoting restricted-domain rows as normal Fable API performance.
Pricing and Real-World Cost
Fable 5 is expensive at the token level ($10 In / $50 Out). Do not use it for tasks with high output token volume and low business margin. Caching, batching, and high task-success rates are required to make it cheaper per solved outcome than Opus 4.8.
Official Pricing Profile
| Model | Input Price | Output Price | Batch Price (In/Out) | Cache Read / Write Price | US-only Multiplier |
|---|---|---|---|---|---|
| Claude Fable 5 | $10.00 | $50.00 | $5.00 / $25.00 | $1.00 / $12.50 (5-min) | 1.1x |
| Claude Opus 4.8 | $5.00 | $25.00 | $2.50 / $12.50 | $0.50 / $6.25 (5-min) | 1.0x |
Worked Cost Examples by Workload
- Agentic coding session: 800K repo input, short logic output. Using a 5-minute cache read ($1/MTok) makes this highly efficient. Context is cheap; reasoning is accurate.
- Document-heavy analysis: 500K legal text input, 10K summary output (Standard API, no cache). This is very expensive. The $50/MTok output multiplier drains budget fast.
- Research workflow: 200K web data input, 5K structured output via Batch API ($5/$25). Cost-optimal. The 50% discount offsets the Fable premium.
Hidden Cost Drivers
Fable 5 uses a newer tokenizer. Pre-Opus 4.7 prompts inflate by up to 35% when migrating. Because adaptive thinking generates hidden reasoning tokens, highly complex prompts consume more output budget than expected. Track your overall Claude usage closely via the billing dashboard because output tokens will dominate your bill.
Comparison: Claude Family and Frontier Alternatives
If 80% of your API traffic is routine, keep a cheaper default like Sonnet 4.6. Route only the hardest 20% of your traffic to Fable 5.
Claude Family Matrix
| Model | Context / Output | Pricing (In/Out) | Safeguards & Retention | Production Suitability |
|---|---|---|---|---|
| Fable 5 | 1M / 128K | $10 / $50 | Refusals on; 30-day retention | Premium routing tier for complex logic |
| Opus 4.8 | 1M / 128K | $5 / $25 | ZDR eligible | Strong everyday default |
| Sonnet 4.6 | 1M / 64K | $3 / $15 | ZDR eligible | Cost-sensitive scaling & fast logic |
Cross-Vendor Checkpoint
- Claude Fable 5: Deepest coding autonomy, but limited by price and 30-day retention.
- GPT-5.5: Broad ecosystem integration, but inconsistent long-context recall.
- Gemini 3.1 Pro: Native Google Cloud ties, but suffers from over-refusals on benign code.
Opus 4.8 remains the better baseline for broadly deployable applications. Use Fable 5 only when Opus fails consecutive reasoning turns. Navigating Claude AI limits requires balancing intelligence against speed; Fable 5's adaptive thinking introduces latency, making it too slow for most interactive chat windows.
API Usage and How to Deploy Claude Fable 5
A blocked Fable request returns an HTTP 200, not an error. As a Claude developer, your application middleware must inspect stop_reason and explicitly handle routing on refusal.
After completing your initial Claude login and generating a workspace key, you cannot simply swap the model ID to Fable 5 and deploy safely. You must update fallback logic, monitor new stop reasons, and manage dynamic effort levels.
Model ID and the First Request
Fable 5 requires the Messages API. The exact string is claude-fable-5. Adaptive thinking is hardcoded on; passing thinking: {"type":"disabled"} throws an error.
import anthropicclient = anthropic.Anthropic()response = client.messages.create( model="claude-fable-5", max_tokens=10000, messages=[{"role": "user", "content": "Analyze this architecture logic."}])print(response.content)What happens when Claude Fable 5 refuses a request?
When Anthropic detects a policy violation, the API halts generation and returns an HTTP 200 response with stop_reason: "refusal". If you configure fallbacks via the native API or AWS, Anthropic automatically retries the prompt on Opus 4.8. On other platforms, you must build client-side middleware to detect the refusal and execute the retry.
Managing Limits and Usage
Fable rate limits dynamically adjust based on cache hits. Query the Rate Limits API and gracefully handle 429 errors using the retry-after header. Always log stop_reason and track usage.iterations to monitor adaptive thinking costs. Pre-baked Opus prompts may trigger refusals on Fable due to heightened sensitivity, so strip aggressive persona prompts before migrating.
Safeguards, Data Retention, and Enterprise Readiness
Fable 5 trades control for capability. It enforces 30-day data retention, breaking compatibility with standard Zero Data Retention (ZDR) architectures.
Visible Safeguards and Invisible Interventions
Anthropic routes sensitive prompts—such as cybersecurity audits or synthetic biology queries—through classifiers. Visible safeguards trigger in less than 5% of average sessions. Beyond visible HTTP-level refusals, system-card analyses suggest an invisible intervention layer that silently degrades performance on restricted frontier-LLM-development requests rather than halting explicitly.
Compliance Decision Tree
If your workload involves legal, healthcare, or financial data that strictly forbids third-party retention, you cannot use Fable 5. It is marked as a "Covered Model" mandating 30-day retention. On AWS Bedrock, opting into this retention means your data temporarily leaves the AWS security boundary, invalidating isolated architectures.
- Does the data mandate Zero Data Retention? (If Yes → Blocked from Fable).
- Is it a restricted cybersecurity workflow? (If Yes → Expect frequent Opus 4.8 fallbacks).
- Does it leave the AWS boundary? (If Yes → Requires secondary InfoSec approval).
Real-World Use Cases and Web-Grounded Workflows
Fable 5 thrives in environments where accurate reasoning is critical, but it fails if its knowledge base is stale. Web-data layers are required for market-facing tasks.
Unlike simple tasks executed in the consumer Claude browser interface, serious Claude work requires structured pipelines and external context.
Best-Fit Workloads
- Long-horizon Claude agents: Untangling legacy codebases by holding multiple files in context simultaneously.
- Research & SEO workflows: Extracting nuance from vast swaths of unstructured text and comparing product features without hallucinating attributes.
- Document-heavy reasoning: Isolating subtle contradictions in 200-page M&A documents better than standard RAG pipelines.
Integrating Olostep for Live Web Data
Building a robust Claude AI agent means confronting knowledge cutoffs. Fable 5 cannot independently scrape a competitor's live pricing page.
Integrating Olostep—a web data API built for AI agents—solves this. For Claude multi agent architectures, Olostep handles the search, scrape, and structuring steps, passing clean JSON directly into Fable 5's reasoning layer. Feeding an agent fresh Olostep data turns it into an active monitor capable of dynamically tracking SEO shifts and market movements.
Production-Readiness Checklist
Never deploy Fable 5 blindly. Verify rate limits, test caching, handle fallback logic, and ensure data compliance before flipping the switch.
Copy this checklist into your launch review before changing model defaults:
- Access & Routing: API access verified, Model ID (
claude-fable-5) confirmed, fallback policy decided, refusal handling implemented. - Budget & Limits: Spend limits set, token-counting baseline run, prompt caching tested, Batch API suitability evaluated, Rate Limits API queried.
- Quality & Latency: Internal eval set created, latency budget tested by effort level, human-review checkpoint defined.
- Governance: Data-retention review complete, sensitive-data routing defined, comprehensive logging enabled (cost, latency, model, stop reason).
Final Decision Framework
Base your model routing decision on task complexity, error sensitivity, latency tolerance, and data retention rules.
- Choose Claude Fable 5 when: Task complexity is high, error cost is high, latency is acceptable, and 30-day retention is legally cleared.
- Choose Claude Opus 4.8 when: You need a broadly deployable default with strong quality, ZDR compliance, and lower costs.
- Choose Claude Sonnet 4.6 when: Throughput, margin, and latency matter more than frontier-level autonomy.
Run a 2-week side-by-side pilot on your hardest tasks before you switch defaults. If that pilot depends on current websites, public docs, or competitor pricing, integrate Olostep as the retrieval and monitoring layer from day one.
FAQ
Is Claude Fable 5 available on Amazon Bedrock?
Yes. However, opting in triggers a 30-day data retention requirement, causing the data to temporarily leave the standard AWS security boundary.
What is the Claude Fable 5 model ID?
The exact API model string is claude-fable-5. You must use this specific string in the Messages API payload.
Does Claude Fable 5 support zero data retention?
No. Anthropic classifies it as a Covered Model. It enforces a strict 30-day retention policy across all access surfaces.
What happens if a request is rerouted to Opus 4.8?
If you enable automated fallbacks, Anthropic intercepts restricted requests and serves them via Opus 4.8. You are billed at the lower Opus token rate for that transaction.
Is Batch API worth using for Claude Fable 5?
Yes. Batch processing halves the $10/$50 token cost to $5/$25, making Fable 5 financially viable for asynchronous background tasks.
Is Claude Fable 5 too slow for interactive chat?
Often, yes. The adaptive thinking mechanism introduces unpredictable latency. Sonnet 4.6 or Opus 4.8 are better fits for synchronous chat windows.
How much can prompt caching reduce cost?
Reading from the cache costs $1/MTok. If you send the same massive codebase repeatedly, caching collapses the input cost by 90%.
When should I add live web data with Olostep?
Integrate Olostep immediately if your agent queries pricing pages, competitor updates, or public documentation. Fable 5 needs external web data APIs to fetch current reality.
Sources:
Anthropic Official Release Announcements (June 2026)
Claude Platform Documentation & Fallback Cookbook
