

You do not need to parse messy HTML to build a reliable data extraction script. In fact, starting with the DOM is often a mistake.
Python web scraping is the automated extraction of structured data from websites using HTTP clients, HTML parsers, or headless browsers. However, modern targets are hostile. According to the Imperva 2025 Bad Bot Report, automated traffic now exceeds human activity at 51%, and strict anti-bot defenses are the new baseline.
The most resilient python web scraper does not just download pages. It hunts for hidden JSON APIs first, parses static HTML only when necessary, and reserves browser automation for complex, JavaScript-heavy domains. This guide walks you through building a production-ready python web scraping pipeline that scales without breaking.
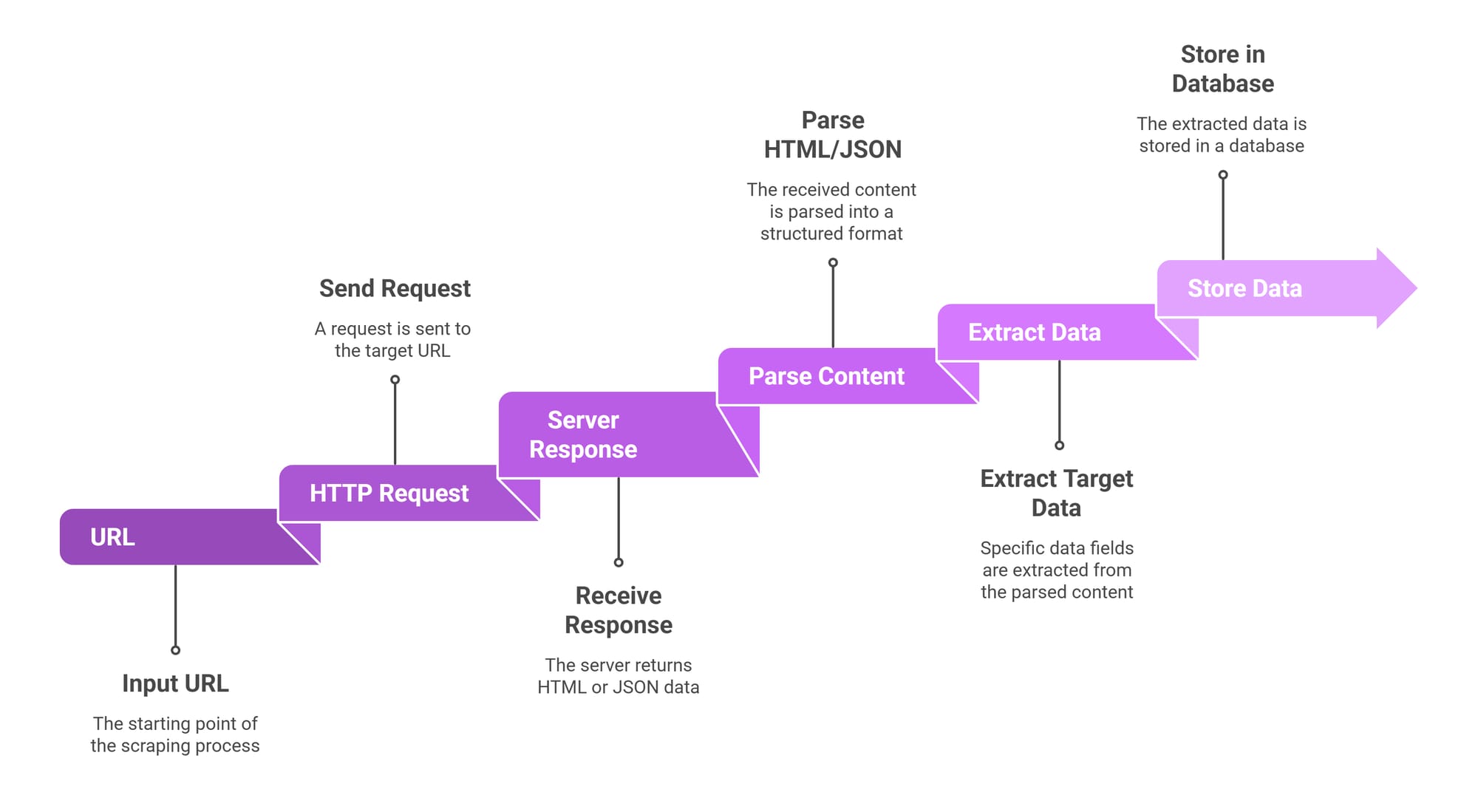
What Is Python Web Scraping?
Python web scraping is the automated process of extracting structured data from websites. It works by sending HTTP requests to a target server, receiving an HTML or JSON response, parsing the content with libraries like BeautifulSoup or HTTPX, and extracting specific data points into a usable format like CSV or databases.
Scraping is a workflow for collecting structured data from HTML, JSON, or rendered pages.
Crawling vs Scraping
Crawling is about discovery. A crawler navigates a site by following links to map its structure. Scraping is about extraction. A python web scraper targets specific pages to pull out discrete data points like prices, names, or reviews.
Three Primary Data Delivery Methods
Websites deliver data in three ways:
- Static HTML: Includes the data directly in the raw source code.
- JSON APIs: Sends raw, structured data to the browser behind the scenes.
- Rendered Content: Uses client-side JavaScript to inject data into the Document Object Model (DOM) only after the page loads.
The Modern Workflow: API First, HTML Second, Browser Last
Do not start with BeautifulSoup by default. Start by analyzing network traffic to find where the data natively originates.
Writing a scraping script is easy. Keeping it alive is hard. The most resilient extraction strategy relies on the lightest, most stable technology available.
The Escalation Ladder
- Hidden JSON APIs
Modern web applications decouple the frontend from backend data. The browser fetches raw JSON and renders it client-side. Intercepting that JSON request bypasses HTML parsing entirely. - Static HTML Parsing
If the server hardcodes data into the HTML response, send a lightweight HTTP request and parse the DOM. - Browser Automation
If the server delivers an empty HTML shell and complex client-side JavaScript builds the data structure, you must use a headless browser to render the page before extracting the DOM. - Asynchronous Crawling Frameworks
When your script handles thousands of pages, concurrent requests, and distributed proxy rotation, shift to an asynchronous framework.
Why the Lightest Method Wins
Headless browsers consume massive memory and trigger advanced anti-bot defenses. Parsing raw HTML is faster but breaks during site redesigns. Calling a JSON API uses minimal bandwidth, ignores visual layout changes, and structures the data automatically.
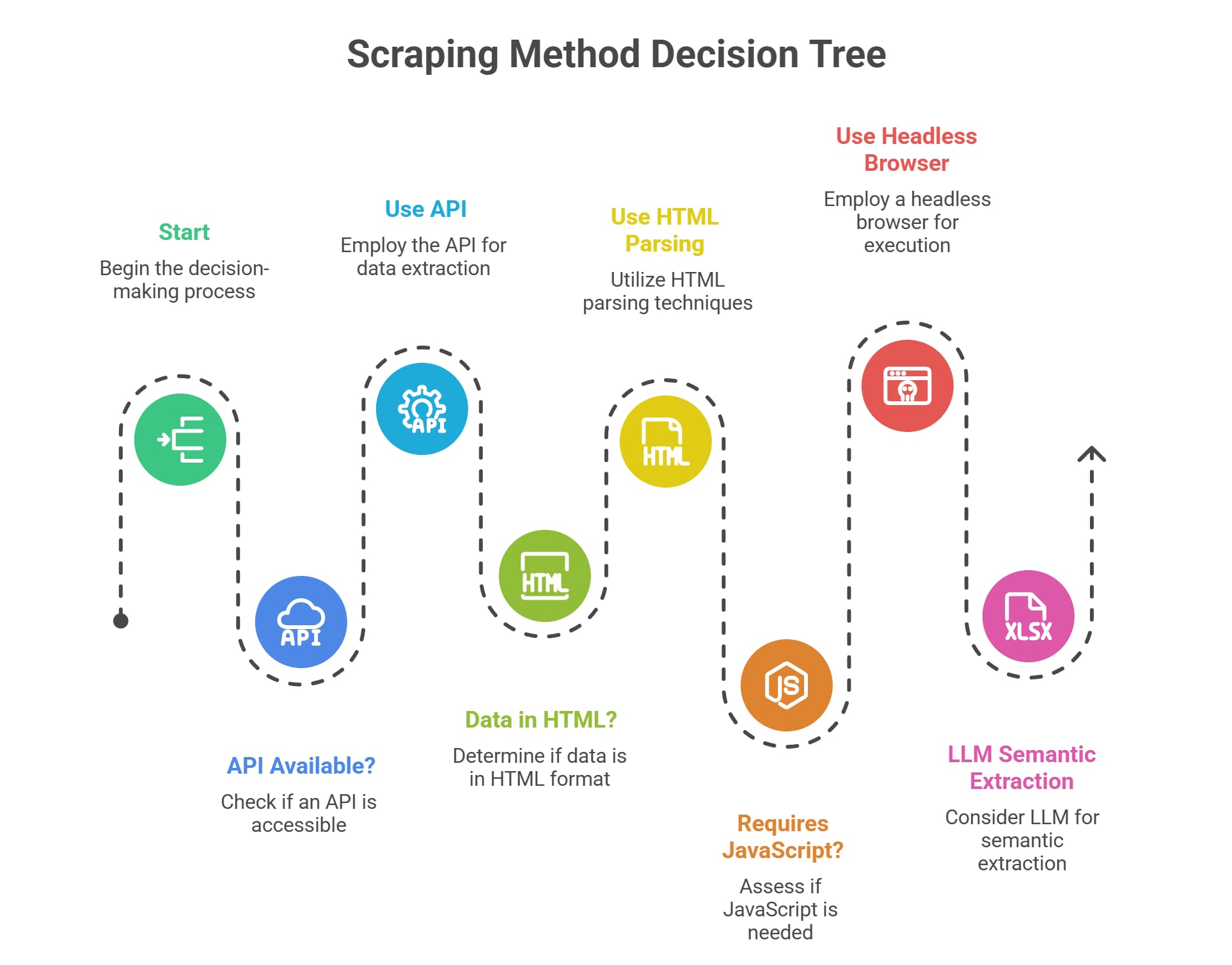
Insider Note on LLMs: When sites actively randomize their CSS selectors to break scrapers, traditional DOM extraction fails. A 2026 arXiv paper suggests that feeding raw, simplified HTML into Large Language Models (LLMs) enables semantic extraction based on meaning rather than rigid code structure. This can bypass anti-scraping layout randomization, though it increases computational costs.
Which Python Scraping Library Is Best?
Pick the exact tool for the specific extraction layer: network, parsing, rendering, or pipeline management.
There is no single "best" python scraping library. Your choice depends entirely on the target's architecture.
HTTPX for Network Requests
While requests dominated Python web scraping for years, httpx is the modern standard. It provides a familiar API while adding native async support and HTTP/2 capabilities, which are crucial for bypassing modern firewall fingerprints.
BeautifulSoup + lxml for HTML Parsing
BeautifulSoup is an interface for navigating static DOM trees via CSS selectors or XPath. It does not fetch pages. Pair it with the lxml parser for maximum execution speed.
Playwright for JavaScript Rendering
Playwright inherently awaits network events and DOM changes. It is fundamentally faster and more reliable than Selenium for modern single-page applications. Use Selenium only when maintaining legacy enterprise scripts.
Scrapy for Large-Scale Crawling
Scrapy is a complete asynchronous application framework. Use it for out-of-the-box concurrency, request throttling, and automated data pipelines. In a 2026 HasData engineering benchmark, Scrapy outperformed standard BeautifulSoup scripts by 39x.
Beginner Python Scraping Tutorial: Example with BeautifulSoup and HTTPX
For static web pages, the HTTPX and BeautifulSoup combination remains the cleanest starting point.
This python web scraper step by step guide covers fetching, parsing, and extracting.
1. Install Required Packages
You need an HTTP client and an HTML parser.pip install httpx beautifulsoup4 lxml
2. Send an HTTP Request
Always instantiate an httpx.Client(). This pools connections and drastically improves performance across multiple requests compared to top-level get() calls.
3. Parse and Extract with CSS Selectors
Pass the text response into BeautifulSoup using the lxml parser. Target elements exactly as you would in CSS using .select_one() for single items or .select() for lists.
4. Clean and Store the Output
Raw web text contains whitespace and missing fields. Handle missing elements gracefully before storing the data to prevent runtime crashes.
import httpxfrom bs4 import BeautifulSoupimport jsonimport logginglogging.basicConfig(level=logging.INFO)def scrape_static_books(url: str): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"} try: # 1. Fetch the page with httpx.Client(timeout=10.0, headers=headers) as client: response = client.get(url) response.raise_for_status() # 2. Parse the HTML soup = BeautifulSoup(response.text, "lxml") books_data = [] # 3. Extract targeting CSS selectors articles = soup.select("article.product_pod") for article in articles: # 4. Clean and handle missing data title_node = article.select_one("h3 a") price_node = article.select_one("p.price_color") books_data.append({ "title": title_node["title"] if title_node else "Unknown", "price": price_node.get_text(strip=True) if price_node else "0.00" }) # 5. Save structured output with open("books.json", "w", encoding="utf-8") as f: json.dump(books_data, f, indent=2) logging.info(f"Successfully scraped {len(books_data)} books.") except httpx.HTTPError as exc: logging.error(f"HTTP Exception for {exc.request.url} - {exc}")if __name__ == "__main__": scrape_static_books("https://books.toscrape.com/")[[MEDIA: Screenshot of a web browser's Inspector tool highlighting an HTML element paired with the CSS selector article.product_pod.]]
How to Scrape a Website Using Python by Calling a Hidden JSON API
If the browser receives JSON in the background, scrape the JSON directly. Ignore the DOM entirely.
When you scrape website data, fighting dynamic HTML layouts is frustrating. If you call the background API directly, you receive a clean, structured dictionary that rarely breaks.
Find the Endpoint
- Open your browser's Developer Tools (Right-click -> Inspect).
- Navigate to the Network tab and filter by Fetch/XHR.
- Refresh the page or trigger a "Load More" action.
- Look for requests returning JSON payloads. Click the request to view the necessary headers and query parameters.
Replicate the Request in Python
Replicate the exact headers like User-Agent and Accept, and pass query parameters using a dictionary. Use response.json() to automatically convert the payload into a Python dictionary.
import httpximport jsondef scrape_hidden_api(): # Discovered via the DevTools Network tab api_url = "https://dummyjson.com/products/search" # Pass parameters cleanly params = {"q": "laptop", "limit": 5} headers = { "Accept": "application/json", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" } with httpx.Client(timeout=10.0) as client: response = client.get(api_url, params=params, headers=headers) response.raise_for_status() # Parse JSON natively data = response.json() extracted = [ { "id": item.get("id"), "name": item.get("title"), "price": item.get("price") } for item in data.get("products", []) ] with open("api_results.jsonl", "w") as f: for record in extracted: f.write(json.dumps(record) + "\n")if __name__ == "__main__": scrape_hidden_api()Scraping Dynamic Websites with Python: When to Use Playwright
Use a headless browser only when the server returns a blank page that requires JavaScript to build the DOM.
Before booting up a browser, check the page source. Many dynamic websites simply embed a large JSON object inside a <script id="__NEXT_DATA__"> tag.
If the data physically requires client-side rendering, httpx will fail. You need Playwright.
Wait for the Right Selector
Never use hardcoded time.sleep() delays. They cause unpredictable failures. Playwright natively supports page.wait_for_selector(), pausing exactly until your target element exists in the DOM.
Extract After Render
Once the element appears, Playwright evaluates the page and extracts the text instantly. You can also save authentication cookies to bypass login screens on subsequent runs.
Cost Trade-offs: A headless browser consumes gigabytes of RAM. An HTTPX script uses megabytes. Reserve Playwright exclusively for targets that demand it.
from playwright.sync_api import sync_playwrightdef scrape_js_rendered_page(url: str): with sync_playwright() as p: # Launch headless Chromium browser = p.chromium.launch(headless=True) page = browser.new_page() page.goto(url) # Wait for dynamic content to physically render page.wait_for_selector(".dynamic-content-class", timeout=10000) # Extract text content = page.locator(".dynamic-content-class").inner_text() print("Extracted content:", content) browser.close()if __name__ == "__main__": scrape_js_rendered_page("https://quotes.toscrape.com/js/")How to Avoid Getting Blocked
Dodging blocks starts with reducing unnecessary request volume, not applying aggressive hacks.
Sites block bots to protect server resources. Firing 100 requests per second with a default python-requests User-Agent guarantees an instant IP ban.
Pacing and Rate Limits
Add randomized delays between requests. Do not hammer servers.
Persistent Sessions
Use httpx.Client() to maintain connection pools. Cache responses locally during development to avoid hitting the live server while testing CSS selectors.
Realistic Headers
Ensure your User-Agent, Accept-Language, and Sec-Fetch-Site headers mimic standard browsers.
Exponential Backoff
Networks drop packets. Implement a retry strategy for temporary 502 and 503 server errors.
Advanced Defenses and Honeypots
A 403 Forbidden error or a CAPTCHA is a clear signal your access pattern looks unnatural. Modern defenses use dynamic traps. Cloudflare's AI Labyrinth dynamically generates honeypot mazes of irrelevant content to trap aggressive bots without triggering hard blocks. When you encounter heavy fingerprinting, stop fighting and evaluate official APIs or managed infrastructure.
When Your Python Web Scraper Stops Scaling: Managed Infrastructure
At a small scale, the code is the challenge. At a large scale, the infrastructure is the bottleneck.
When scaling from 100 pages to 100,000 pages daily, IP blocking, CAPTCHA friction, and selector churn consume your engineering bandwidth. Industry guidance from providers like ScrapeHero shows that unmanaged scrapers suffer downtime when target site layout changes, while managing headless browsers drains developer hours.
Build vs. Buy for Public Web Data
Building your own pipeline requires renting servers, managing rotating residential proxy pools, patching headless browser fingerprints, and constantly monitoring success rates.
Managed Scraping Infrastructure
Companies requiring reliable data shift to managed infrastructure to offload proxies, browsers, and anti-bot handling. This routes requests through optimized proxy networks and handles CAPTCHAs server-side.
Instead of running a massive Playwright cluster locally, you send a single API request to an endpoint that returns clean HTML or structured JSON. Platforms like Olostep handle proxy rotation, headless browser management, and anti-bot bypass mechanisms natively, keeping your Python pipeline strictly API-first.
From Script to Data Extraction Pipeline
A reliable scraper is a strict data pipeline with validation, not just a script with selectors.
Define a Stable Schema
Never dump raw variables directly into a file. Define exact fields like id, price, and timestamp, and enforce them.
Secure Storage
Raw CSV files corrupt easily if scraped text contains unescaped commas. Use JSON Lines (JSONL) for file-based logs. For structured querying, route the data directly into a local SQLite database or a remote PostgreSQL instance.
Deduplicate and Validate
- Upserts: Sites display duplicate items across pagination. Use a unique key like a product SKU to
INSERT OR REPLACEdata, preventing duplicates. - Validation Rules: If the
pricefield returnsNonefor 50 consecutive items, the CSS selector broke. Fail loudly and halt the pipeline. - Timestamps: Always append an extraction timestamp to track when data was observed.
import sqlite3import datetimedef store_scraped_data(records: list): conn = sqlite3.connect("scraper_pipeline.db") cursor = conn.cursor() cursor.execute(""" CREATE TABLE IF NOT EXISTS products ( sku TEXT UNIQUE, title TEXT, price REAL, last_scraped TIMESTAMP ) """) scrape_time = datetime.datetime.now(datetime.timezone.utc) for record in records: # Strict validation if not record.get("sku") or record.get("price") is None: continue # Upsert logic cursor.execute(""" INSERT INTO products (sku, title, price, last_scraped) VALUES (?, ?, ?, ?) ON CONFLICT(sku) DO UPDATE SET price = excluded.price, last_scraped = excluded.last_scraped """, (record["sku"], record["title"], record["price"], scrape_time)) conn.commit() conn.close()# Example payloadstore_scraped_data([{"sku": "123-A", "title": "Laptop", "price": 999.99}])Is Web Scraping Legal?
Scraping carries risks based on the data type, access method, and output usage.
Note: Educational context, not legal advice.
Scraping publicly available data without bypassing security controls is generally permissible. Extracting personal data, circumventing authentication, or copying copyrighted material carries substantial risk.
Ask these questions before extracting:
- Is the data public? Public data is vastly safer than data hidden behind a login wall.
- Are you logged in? Logging in means you agree to the site's Terms of Service. Violating those terms creates direct contract liability.
- Does it include personal data? Extracting names or emails triggers strict privacy laws like GDPR globally.
- Did you bypass access controls? Circumventing cryptographic APIs triggers DMCA anti-circumvention claims.
Troubleshooting Common Python Web Scraping Errors
Most extraction failures are method-selection errors, not code bugs.
403 Forbidden
The server flagged you as a bot. Pass a real User-Agent string, use httpx.Client() for connection pooling, and throttle your request rate.
Empty HTML or Missing Data
The target data is rendering client-side. Check the DevTools Network tab for a hidden JSON API. If it does not exist, escalate to Playwright and wait for the DOM to render.
Parser Cannot Find the Element
If soup.select_one() returns None, the layout changed or you targeted a browser-injected class. Print soup.prettify() locally to verify the class name actually exists in the raw HTML payload.
Encoding Issues
If text looks garbled (é), explicitly pass encoding="utf-8" when writing files and rely on HTTPX's native charset detection.
FAQ
What is web scraping in Python?
It is the automated process of using Python libraries to request, parse, and extract structured data from websites, typically transforming raw HTML or JSON into databases.
Is web scraping legal?
Scraping public, non-personal data is generally legal. Scraping personal information, violating authenticated Terms of Service, or bypassing security controls creates significant legal liability.
Which Python library is best for web scraping?
Use httpx for network requests, BeautifulSoup for static HTML parsing, Playwright for JavaScript rendering, and Scrapy for large-scale crawling.
Can Python scrape JavaScript websites?
Yes. Check the browser's Network tab first to extract the underlying JSON API via HTTPX. If client-side rendering is strictly required, use Playwright to execute the JavaScript.
What is BeautifulSoup used for?
BeautifulSoup creates a navigable tree out of HTML and XML documents. It allows developers to search and extract specific text and attributes using CSS selectors or XPath.
How do you scrape a website without getting blocked?
Respect rate limits, use randomized delays, send realistic headers, cache local responses, and use managed proxy infrastructure or official APIs for high-volume extraction.
Final Takeaway: Start With the Lightest Working Method
The ideal Python web scraping workflow prioritizes APIs, uses static HTML as a backup, and reserves browser automation for emergencies.
Building a python web scraper is simple; building a durable data extraction system requires discipline. Stop defaulting to raw HTML parsing. Hunt for the underlying API first. Drop down to static HTML parsing with HTTPX and BeautifulSoup only when necessary, and deploy Playwright exclusively for complex JavaScript interfaces.
Treat your code as a strict data pipeline. Enforce schema validation, deduplicate database entries, and implement alerting for layout changes. If scaling becomes an infrastructure burden, transition to managed platforms like Olostep to maintain your API-first pipeline without managing proxy networks.
