Scraping a website used to be straightforward. You'd send a request, get the HTML, and parse it. Done. But today, the game has completely changed. Simply grabbing the raw HTML is often just the first step, and it's rarely the hardest one. The real challenge is getting past sophisticated anti-bot measures and dealing with websites that load content on the fly.
This guide tackles the problem head-on. We'll start by exploring why modern web scraping is so difficult, then dive into multiple approaches—from basic DIY scripts to robust API-driven solutions. Finally, we'll walk through a step-by-step tutorial using Python to build a resilient, ethical, and effective web scraper.
The Problem: Why Modern Web Scraping Is So Hard
If you're just getting into web scraping, you'll find it’s a lot trickier than it was even a few years ago. It’s no longer a simple matter of sending an HTTP request and sifting through the response. Companies now rely heavily on web data for everything—from tracking competitor prices and doing market research to feeding data into their AI models.
Because this data is so valuable, website owners have thrown up some serious defenses to protect it. This has turned scraping into a constant battle, a technical cat-and-mouse game where you’re always trying to stay one step ahead. The roadblocks you'll hit are designed specifically to stop scrapers in their tracks.
Websites Are More Complex Than Ever
Many of the websites you use every day are Single Page Applications (SPAs) built with frameworks like React or Vue.js. These aren't like the static sites of the past. Instead of loading everything at once, they pull in data using JavaScript as you scroll and click around.
This is a huge problem for basic scrapers. A simple GET request won't see any of that dynamic content because it only loads after a browser runs the site's JavaScript. Your options are to either painstakingly reverse-engineer the website's private APIs (if you can even find them) or use a headless browser to render the page like a real user would. Headless browsers work, but they are incredibly slow and chew through memory and CPU.
The Rise of Smart Anti-Bot Systems
The other giant hurdle is the widespread use of anti-bot services. These systems are incredibly good at telling the difference between a real person browsing a site and an automated script you've written.
They use a whole bag of tricks to spot and block you:
- IP Reputation: If your IP address comes from a data center, it’s an immediate red flag. They'll often block you outright.
- Browser Fingerprinting: These systems check tiny details about your setup—your browser version, screen size, even the fonts you have installed—to create a unique signature that can give away your scraper.
- Behavioral Analysis: They're even watching how you navigate. They track mouse movements, how fast you type, and where you click to see if your behavior looks robotic.
- CAPTCHAs: And of course, there are the classic challenges designed to be simple for people but a nightmare for bots.
The demand for web data is exploding. The global web scraping market is expected to hit $1.03 billion in 2025 and nearly double by 2030. This growth is what fuels the arms race between scrapers and anti-bot companies. With bot traffic making up almost half of all internet activity, it's a massive battlefield. You can read the full research about these industry benchmarks to see just how big the scale of automation is online.
The core problem isn't just fetching a webpage; it's getting clean, structured, and reliable data at scale without getting blocked. This is where a dedicated scraping API like Olostep becomes essential, handling the complex backend work so you can focus purely on the data.
Step-by-Step Solution: Making Your First Scrape With Python
Alright, enough theory. The best way to really get a feel for this stuff is to dive in and write some code. Let's walk through your first successful data extraction request using Python and the Olostep API. I’ll guide you through the whole process, from grabbing your API key to sending the request and looking at the raw HTML that comes back.

First, Grab Your API Key
Before you can do anything, you need to authenticate yourself. Every call you make to Olostep requires an API key, which is just a unique string that proves you have an account.
Finding your key is simple:
- Log into your Olostep dashboard.
- Look for the "API Keys" section in the main menu.
- Your key will be right there, ready to copy with a click.
Pro-tip: Treat this key like a password. Anyone who gets their hands on it can make requests on your account and burn through your credits. A good habit to get into is storing it as an environment variable instead of hardcoding it directly into your scripts.
Putting Together the Python Request
With your API key ready, it's time to fire up your code editor. We'll be using the requests library, which is pretty much the go-to tool for making HTTP requests in Python. If you don't have it installed for some reason, just run a quick pip command:
pip install requestsNow, let's build the script. We'll start by targeting a simple e-commerce product page to get its HTML content. This is a classic starting point for projects like price monitoring or gathering product specs. If you're tackling something bigger, like Amazon, we have a more in-depth guide on how to scrape Amazon product data you can check out later.
Our script is going to send a POST request to the Olostep API endpoint: https://api.olostep.com/v1/scrapes.
Why a
POSTrequest? We're essentially creating a new scrape job, and we need to send a payload with instructions (like the URL to scrape). APOSTrequest is the standard way to send that kind of data in the request body.
The Full Code Example
Here’s a complete script you can copy and paste to run your first scrape. Just remember to swap out 'YOUR_API_KEY' with the actual key you copied from your dashboard.
import requests
import json
import os
# Best practice: store your API key as an environment variable
# Replace with your actual key if not using environment variables
api_key = os.getenv('OLOSTEP_API_KEY', 'YOUR_API_KEY')
# The Olostep API endpoint for creating a new scrape job
api_url = 'https://api.olostep.com/v1/scrapes'
# Define the headers for your request
# The Authorization header sends your API key
# The Content-Type header tells the API we're sending JSON data
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
# Construct the payload with the target URL
# For this example, we're targeting a sample e-commerce site
payload = {
'url': 'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html'
}
print("Sending request to Olostep API...")
try:
# Send the POST request to the API with a reasonable timeout
response = requests.post(api_url, headers=headers, json=payload, timeout=30)
# Raise an exception for bad status codes (4xx or 5xx)
response.raise_for_status()
# Parse the JSON response from the API
response_data = response.json()
# --- Example Successful Response Payload ---
# {
# "status": "completed",
# "credits": 1,
# "data": "<!DOCTYPE html><html><head>...",
# "response_headers": {
# "content-type": "text/html; charset=utf-8",
# ...
# },
# "status_code": 200
# }
# Print the raw HTML content of the target page
# The HTML is located in the 'data' field of the response
if 'data' in response_data:
print("Success! Received HTML content (first 500 characters):")
print(response_data['data'][:500] + '...')
else:
print("Request was successful, but no 'data' key found in response.")
print("Full response:", response_data)
except requests.exceptions.HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
print(f"Status Code: {response.status_code}")
# The response from the API often contains useful error details
print(f"Response content: {response.text}")
except requests.exceptions.Timeout:
print("The request timed out. The server may be slow to respond.")
except requests.exceptions.RequestException as req_err:
print(f"A request error occurred: {req_err}")
except KeyError:
print("Could not find the 'data' key in the response. Full response:")
print(response.json())
except json.JSONDecodeError:
print("Failed to decode JSON from response. The response may not be valid JSON.")
print(f"Raw response: {response.text}")Breaking Down the Code and the Response
So, what’s actually happening in that script? Let's quickly go through it.
- Headers: We're setting two crucial headers. The
Authorizationheader securely sends yourapi_keyusing theBearertoken format. TheContent-Type: application/jsonheader is just us telling the Olostep server that the data we're sending is in JSON format. - Payload: This is a simple Python dictionary that contains our instructions. The only thing we absolutely need is the
urlkey, which tells Olostep what page we want to scrape. - The Request: The line
requests.post()is where the magic happens. It bundles up the API endpoint, our headers, and the payload and sends it all over to Olostep's servers. - The Response: If everything goes smoothly, the API sends back a 200 OK status and a JSON object. The raw HTML of the page you requested is neatly tucked away inside the
datakey of that JSON. Our script grabs it withresponse_data['data']and prints it right to your console.
Getting this script to run successfully is a huge first step. You've just pulled down the complete source code of a webpage without your own IP address ever having to touch the target's server.
Navigating Advanced Scraping Challenges: Anti-Bot Bypassing
Pulling data from a simple, static page is one thing. But the moment you start targeting real-world websites, you'll discover it’s not always so straightforward. Most modern sites are designed to create a smooth user experience, but those same features can become major roadblocks for scrapers.
We're mainly talking about two big hurdles: dynamic content loaded with JavaScript and aggressive anti-bot systems. Learning to navigate these is what separates a beginner from a pro.
Scraping Dynamic JavaScript-Powered Websites
Ever scraped a page only to find the data you need is completely missing? You're likely dealing with a JavaScript-powered website. Many e-commerce and social media platforms load their core content after the initial page loads. Your script gets the initial HTML shell, but the juicy data only appears once the JavaScript runs in a browser.
Olostep handles this with a single instruction: render_js. By adding "render_js": true to your request, you’re telling the API to load the page in a real browser, wait for all that JavaScript to do its thing, and then send you back the final, fully-rendered HTML.
import requests
import json
import os
# Your Olostep API key goes here
api_key = os.getenv('OLOSTEP_API_KEY', 'YOUR_API_KEY')
api_url = 'https://api.olostep.com/v1/scrapes'
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
# The magic happens here: add 'render_js': True
payload = {
'url': 'https://quotes.toscrape.com/js/', # A site built to require JS
'render_js': True
}
try:
response = requests.post(api_url, headers=headers, json=payload, timeout=60) # JS rendering takes longer
response.raise_for_status()
response_data = response.json()
print("Successfully retrieved JS-rendered page content:")
print(response_data.get('data')[:500] + '...')
except requests.exceptions.HTTPError as http_err:
print(f"Bummer, an HTTP error occurred: {http_err}")
print(f"Here's what the server said: {response.text}")
except requests.exceptions.RequestException as req_err:
print(f"Something went wrong with the request: {req_err}")If you tried scraping that URL without render_js, you'd get back a page with no quotes. With it, you get the complete HTML, data and all. Problem solved.
Defeating Anti-Bot Measures with Proxies and Headers
Getting blocked is the most common headache in web scraping. Websites deploy an arsenal of tools to spot and shut down automated traffic, from simple IP checks to analyzing your request's digital fingerprint.
Using Residential Proxies
The single most effective way to fly under the radar is by using residential proxies. These are IP addresses assigned to real home internet connections, making your requests look like they're coming from a regular person browsing the web, not a server in a data center.
With Olostep, all you have to do is set the proxy_type parameter to 'residential'.
- When should you use them? Reach for residential proxies when you're targeting high-security sites notorious for blocking scrapers. Think major retailers, airline ticket sites, and social media platforms.
Customizing Your Request Headers
Another dead giveaway for scrapers is the User-Agent header. This little string of text tells the server what kind of browser and operating system you’re using. To look more human, you should send a custom User-Agent. Olostep lets you pass any headers you want directly in your request.
Here’s a complete example that brings it all together—we'll use a residential proxy and a custom header for a truly robust request.
import requests
import json
import os
api_key = os.getenv('OLOSTEP_API_KEY', 'YOUR_API_KEY')
api_url = 'https://api.olostep.com/v1/scrapes'
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
# A common User-Agent for Chrome on a Windows machine
custom_user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
payload = {
'url': 'https://www.amazon.com/dp/B08P2H5L72', # A tough target
'proxy_type': 'residential', # Use a residential IP address
'headers': {
'User-Agent': custom_user_agent,
'Accept-Language': 'en-US,en;q=0.9'
}
}
try:
response = requests.post(api_url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_data = response.json()
print("Success! We got the page.")
# print(response_data.get('data')) # Uncomment to see the full HTML
except requests.exceptions.HTTPError as http_err:
print(f"HTTP error: {http_err}")
print(f"Content: {response.text}")
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")Key Takeaway: The real power comes from combining these tools. JavaScript rendering, residential proxies, and custom headers are your core toolkit. For a much deeper look into these kinds of evasion tactics, check out our guide on how to scrape without getting blocked.
Building a Resilient and Ethical Scraper
Anyone can write a script that runs once. The mark of a pro is building a tool that runs reliably over and over again. This means handling network hiccups, server errors, and rate limits, all while playing by the website's rules.
Troubleshooting Common Failures
You'll inevitably encounter errors. Here’s how to handle the most common ones:
- CAPTCHAs: These are designed to stop bots. A good scraping API like Olostep handles most CAPTCHAs automatically behind the scenes. If you're building from scratch, this is a major, often insurmountable, hurdle.
- 403 Forbidden / 429 Too Many Requests: These mean you've been identified as a bot or are sending requests too quickly. The solution is to use high-quality residential proxies, rotate user agents, and add delays between requests.
- 5xx Server Errors (500, 502, 503): These indicate a problem with the target server, not your script. The best strategy is to wait and retry the request after a short delay.
- Timeouts: Your request took too long. This can be due to a slow website, a slow proxy, or complex JavaScript rendering. Increase your request timeout and ensure you're using a reliable connection or proxy service.
Handling Errors and Retries Gracefully
A resilient scraper anticipates failures and knows how to try again intelligently. We can build a retry loop that uses exponential backoff: when a request fails, wait before trying again, and double the waiting period with each subsequent failure. This gives the server a moment to breathe.
Here’s a more production-ready Python script that puts this logic into practice.
import requests
import json
import time
import os
# Replace with your actual Olostep API key
api_key = os.getenv('OLOSTEP_API_KEY', 'YOUR_API_KEY')
api_url = 'https://api.olostep.com/v1/scrapes'
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
payload = {
'url': 'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html'
}
# --- Retry Logic Configuration ---
max_retries = 3
base_backoff_seconds = 2
for attempt in range(max_retries):
try:
print(f"Attempt {attempt + 1} of {max_retries}...")
response = requests.post(api_url, headers=headers, json=payload, timeout=30)
# Retry on specific server-side errors or rate limiting
if response.status_code in [429, 500, 502, 503, 504]:
print(f"Received status {response.status_code}. Retrying in {base_backoff_seconds * (2 ** attempt)}s...")
time.sleep(base_backoff_seconds * (2 ** attempt))
continue
# For other errors (like 403 Forbidden), raise an exception immediately
response.raise_for_status()
response_data = response.json()
print("Success! Retrieved data:")
print(response_data.get('data')[:200] + '...') # Print first 200 chars
break # Exit the loop on success
except requests.exceptions.HTTPError as e:
print(f"HTTP Error: {e.response.status_code} {e.response.reason}")
print(f"Content: {e.response.text}")
# Decide if this error is worth retrying, for now we break
break
except requests.exceptions.RequestException as e:
print(f"A request error occurred: {e}")
if attempt < max_retries - 1:
wait_time = base_backoff_seconds * (2 ** attempt)
print(f"Retrying in {wait_time}s...")
time.sleep(wait_time)
else:
print("Max retries reached. Aborting.")
break # Exit loop after max retries
else:
# This block runs if the loop completes without a `break`
print("All retry attempts failed.")The Rules of Ethical and Legal Scraping
Technical skill is only half the equation. Knowing how to scrape websites ethically is what separates a sustainable data project from one that gets you blocked or, worse, in legal hot water.
1. Respect robots.txt
Your first stop should always be the robots.txt file (e.g., example.com/robots.txt). This file outlines the rules for automated bots. While not legally binding, ignoring it is a surefire way to get blocked. Honor Disallow directives and Crawl-delay settings.
2. Don't Overload Servers Be a good internet citizen. Scrape at a reasonable rate, introduce random delays between requests, and consider scraping during off-peak hours to minimize impact on the website's performance.
3. Avoid Personal Data Data privacy laws like GDPR and CCPA have strict rules about collecting personally identifiable information (PII). The golden rule is simple: do not scrape PII (names, emails, phone numbers) unless you have a clear legal basis and consent. Stick to public, non-personal data.
4. Check Terms of Service Review the website's Terms of Service for any clauses that explicitly forbid automated data collection. Violating these terms can lead to legal action.
The legal landscape is always evolving. For commercial projects, consulting with a legal professional is highly recommended to ensure compliance. Citing your data sources and being transparent about your methods are also key components of maintaining E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness).
Comparing Alternatives: Olostep vs. Other Scraping APIs
While we've been focusing on Olostep, it’s always smart to know what else is out there. The web scraping API market is full of options, and the "best" one really depends on what you're trying to build.
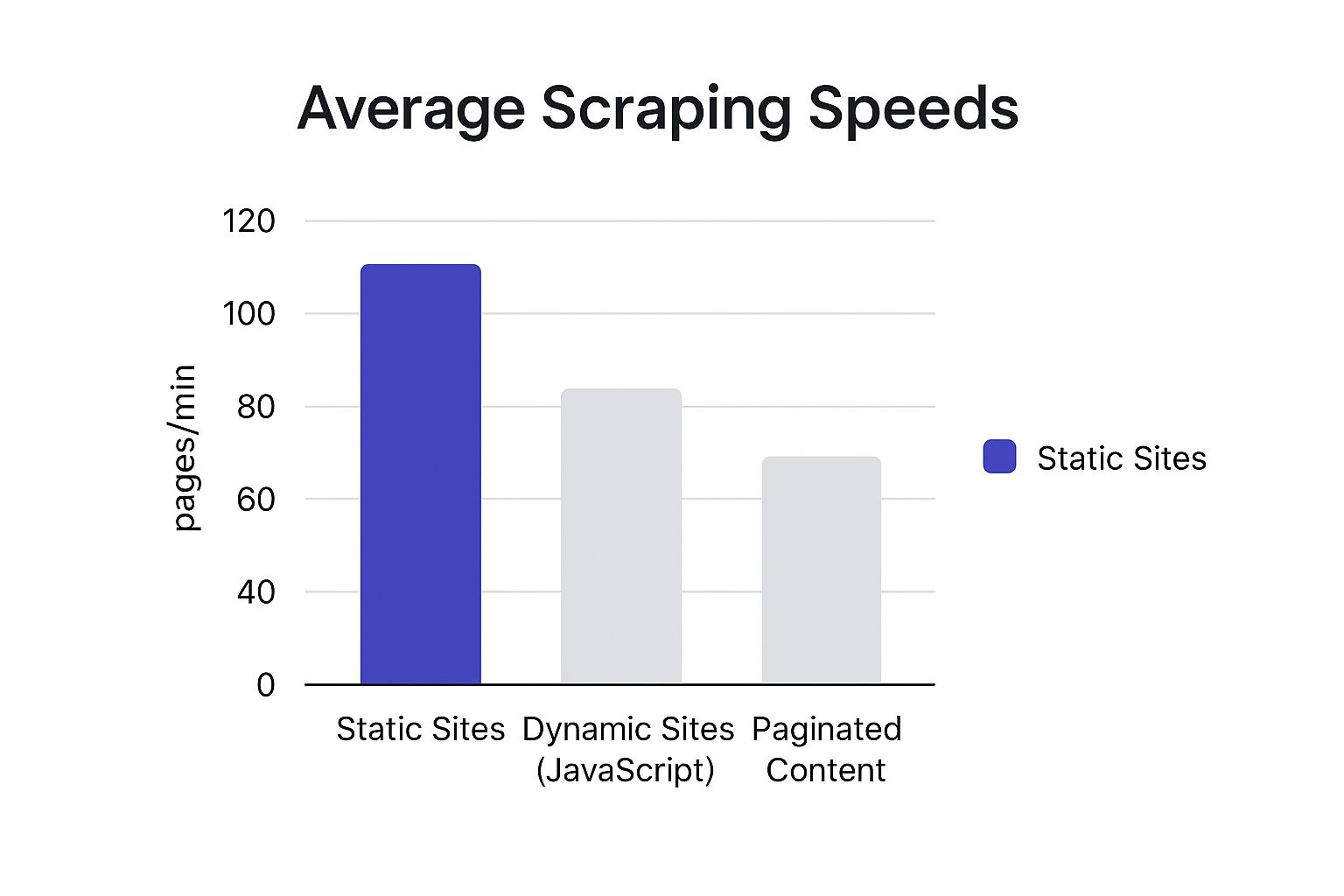
Web Scraping API Feature Comparison
To put this all into perspective, here is a fair comparison of some of the most popular APIs side-by-side.
| Feature | Olostep | ScrapingBee | Bright Data | ScraperAPI | Scrapfly |
|---|---|---|---|---|---|
| Pricing Model | Per-request | Per-request | Bandwidth/IP | Per-request | Hybrid (Bandwidth + Features) |
| Proxy Types | Datacenter, Residential | Datacenter, Residential | All Types | Residential | Residential |
| JS Rendering | Yes | Yes | Yes | Yes | Yes |
| CAPTCHA Solving | Built-in | Built-in | Built-in | Built-in | Built-in |
| Ideal Use Case | AI startups, developers needing simplicity and power. | General purpose scraping, good for freelancers. | Large-scale enterprise data extraction. | Developers needing a simple, easy-to-use API. | Advanced users needing fine-grained control. |
- ScrapingBee is a solid all-rounder, popular for its ease of use and clear documentation.
- Bright Data is an enterprise-grade solution known for its massive and diverse proxy network, ideal for huge-scale operations.
- ScraperAPI focuses on simplicity, making it very accessible for developers who want a straightforward API without many complex options.
- Scrapfly offers advanced features and a unique pricing model, appealing to users who need deep control over their scraping jobs.
Our Takeaway: Olostep is designed for developers and AI companies who need reliable, structured data without getting bogged down in complex configurations. It strikes a great balance between power, ease of use, and predictable pricing.
Of course, you could always try to build everything yourself using a framework like Selenium or Scrapy. While these tools give you total control, you become responsible for managing proxies, rotating user agents, solving CAPTCHAs, and handling blocks—exactly the headache that a good web scraping API is designed to solve.
Final Checklist and Next Steps
Before you launch your next scraping project, run through this checklist to ensure you're set up for success.
Pre-Launch Checklist
- Define Data Requirements: Be specific about the exact data fields you need to extract (e.g., product title, price, stock status).
- Check
robots.txt: Visityourtarget.com/robots.txtand confirm you are respecting the site's rules. - Review Terms of Service: Skim the ToS for any clauses prohibiting automated access.
- Choose Your Tools: Select an API like Olostep that fits your target's complexity (JS rendering, residential proxies).
- Plan Data Storage: Decide how you will store the extracted data (CSV, JSON, database). There are many effective strategies for organizing web content to consider.
Next Steps
- Start Small: Begin by scraping a single page to test your logic before scaling up.
- Parse the HTML: Use a library like BeautifulSoup (Python) to parse the HTML returned by the API and extract your target data.
- Implement Error Handling: Add robust retry logic and error handling to make your scraper resilient.
- Scale Responsibly: If scraping multiple pages, add delays between requests and scale up your operation gradually.
With this guide, you have a comprehensive roadmap. The best way to learn is by doing.
Ready to see how simple this can be? Olostep gives you all the tools needed to navigate these scraping challenges. Sign up today and get 500 free credits to kick off your next data project.