

Every data-driven project starts with one core problem: the information you need is trapped on someone else's website. If you want to know how to build a web scraper, you need to understand the mechanics of extraction. A web scraper programmatically mimics a browser to retrieve and structure this information.
But before you write a single line of Python, you need a strategy. I once copied a parsing tutorial perfectly, pointed it at a modern webpage, and received a completely empty HTML response because the data was rendered by JavaScript. If you start your extraction process in the browser rather than the script, you avoid this trap entirely. You will learn the classic Python extraction method, a hidden API shortcut, and how to scale your simple script into an automated data pipeline.
Automated bots made up 51% of all global web traffic in 2024. This is why websites are increasingly aggressive about blocking naive scraping scripts (Source: Imperva 2025 Bad Bot Report).
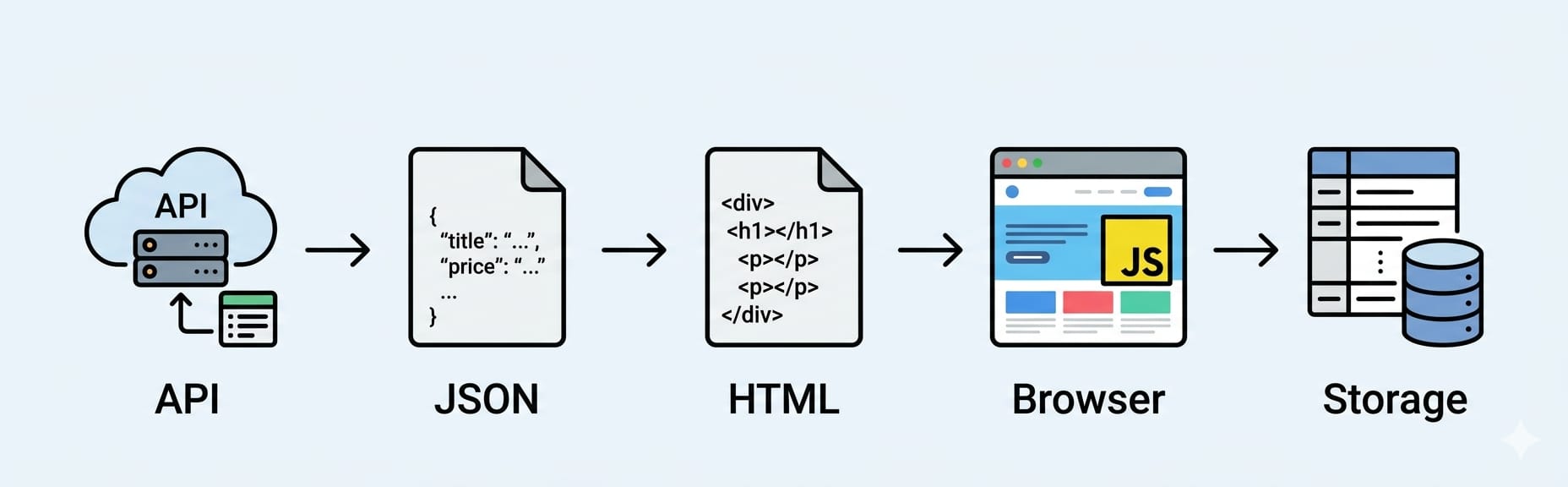
What is a Web Scraper?
A web scraper is an automated script that sends an HTTP request to a webpage, extracts specific structured data fields from the HTML or JSON response, and saves that data into a usable format like CSV or a database.
Web Scraper vs. Web Crawler vs. API
These terms describe different web data acquisition methods.
- Web crawler: Discovers and maps URLs. A crawler finds links without extracting specific page content.
- Web scraper: Extracts specific data fields from a known URL.
- API (Application Programming Interface): An official channel provided by a platform to return structured data directly.
Automated web scraping makes sense when you need public page data for research or monitoring, but no official API exists. It allows you to automate structured extraction directly from the frontend. If a site provides a public API, use it first.
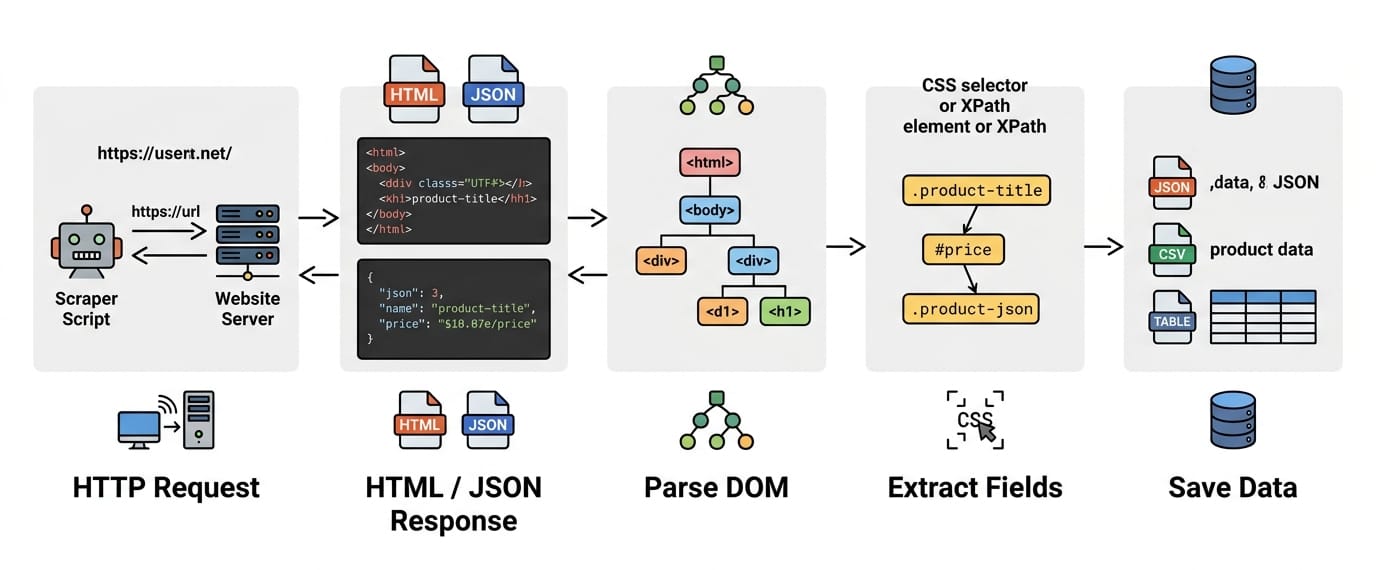
How Web Scraping Works
The core extraction workflow is: Send an HTTP request -> Receive the HTML/JSON response -> Parse the DOM -> Select elements -> Store the structured data.
Web scraping programmatically replicates what your browser does manually. You request a URL, receive text back, locate the targeted text, and save it.
Send an HTTP Request
Your script asks a server for a page using a specific URL. In Python, the Requests library handles sending this underlying HTTP request.
Download the HTML or JSON Response
The server returns a payload. For traditional pages, this payload is raw HTML markup. If the page requests data in the background, the payload is often a cleanly formatted JSON object. The server also returns a status code. You want a 200 (Success) and must avoid a 403 (Forbidden) or a 429 (Too Many Requests).
Parse the DOM
HTML is just a long string of text. The Document Object Model (DOM) is the tree-like structure a browser builds from that HTML. To write targeted rules, you must convert the raw HTML string into a searchable DOM tree. BeautifulSoup is the standard Python parser for this job.
Extract Data with CSS Selectors
CSS selectors are rules targeting specific DOM elements. The exact selectors frontend developers use to style a webpage (like .product-title or #price-tag) allow scrapers to locate the exact text nodes you want to extract.
Store the Output
Extracted data disappears when the script finishes running unless you save it. JSON is the default format because it seamlessly handles nested relationships. CSV works for flat spreadsheet exports. SQLite is ideal for persistent database storage.
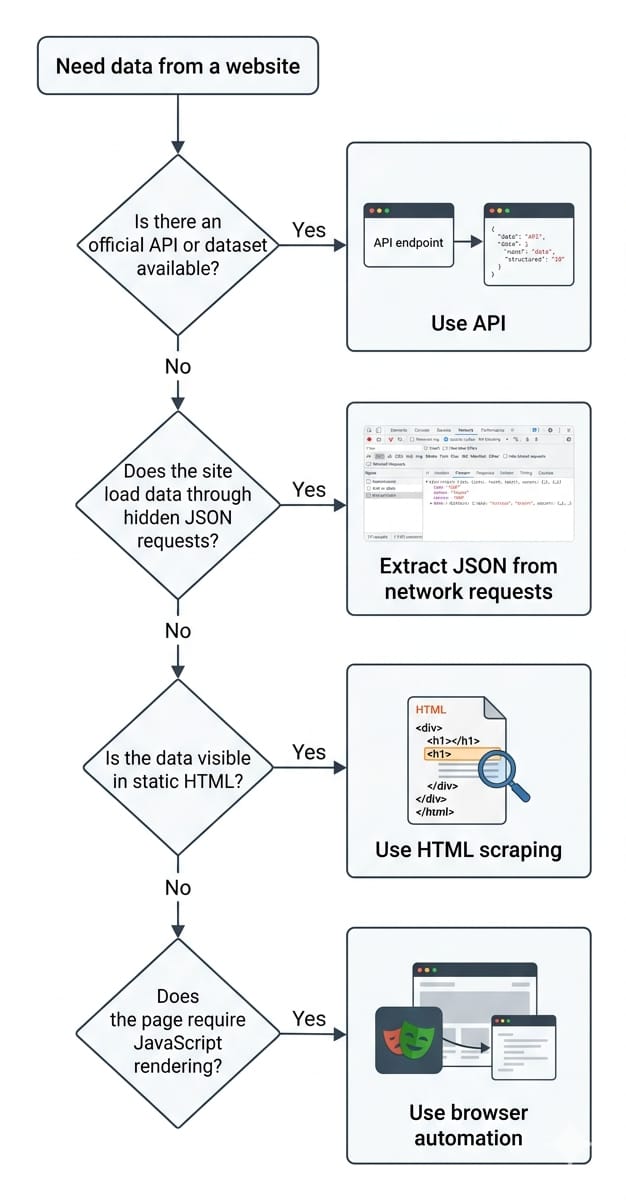
Before You Write Code: Choose the Right Scraping Method
Always use the lightest extraction method that returns structured data reliably.
Beginners often rush straight into writing HTML parsers. Professionals audit the website first to find the path of least resistance.
Check for an Official API or Dataset
Look for developer documentation, a public sitemap, or downloadable datasets. Supported data sources do not break when a frontend designer changes a CSS class name.
Inspect the Network Tab for Hidden JSON
Open your browser Developer Tools, navigate to the Network tab, reload the page, and filter traffic by XHR or Fetch. You are looking for background requests returning JSON responses. Modern web applications load an empty HTML shell and populate it by fetching a JSON file. Finding this JSON allows you to bypass HTML parsing entirely.
Scrape the HTML Only if Necessary
If the page is static and server-rendered, the data lives directly in the visible HTML markup. In this scenario, combining the Requests library with BeautifulSoup is the correct lightweight approach.
Use Browser Automation for JavaScript Pages
Escalate to heavy tools only when required. The path is strict: API first, hidden JSON second, HTML parsing third, and browser automation last. If a page requires JavaScript execution to render content, you must load an actual browser engine. Playwright is the default modern option. Selenium is an older alternative that remains viable if it already exists in your QA stack.
How to Build a Web Scraper with Python
A basic Python scraper loops over HTML elements that match your chosen CSS selectors and appends the extracted text to a structured list.
We will build a simple beginner web scraping tutorial targeting a safe static page. This script intentionally strips away modern web complexity so you can master the core mechanics.
Install Python and the Required Packages
Ensure you are running Python 3.12 or newer. Open your terminal and install the HTTP client and HTML parser.
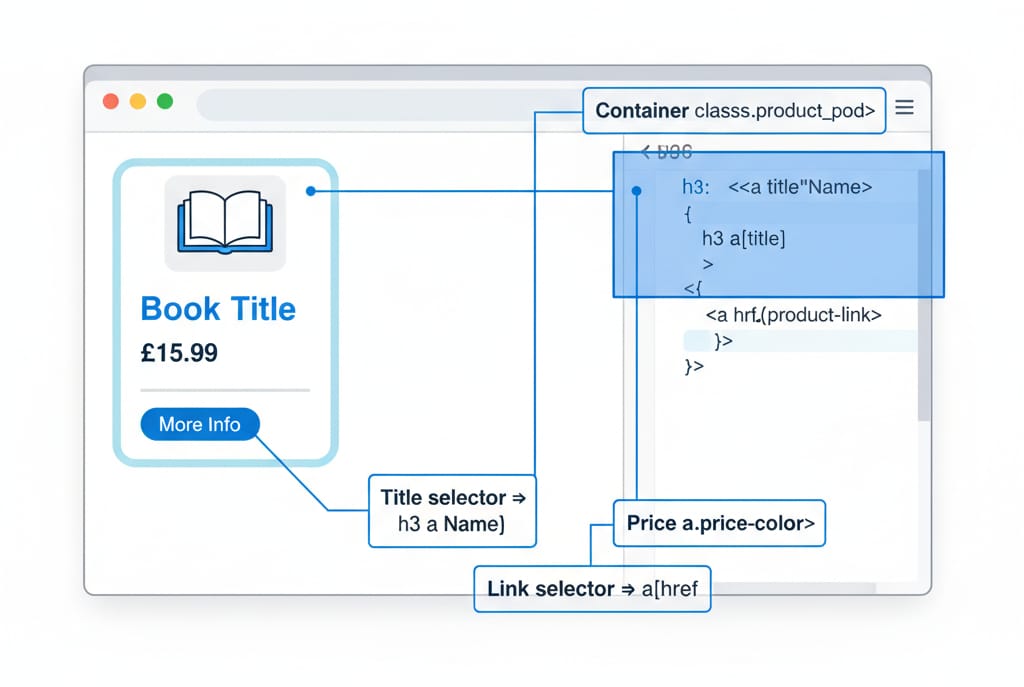
pip install requests beautifulsoup4Inspect the HTML and Identify Selectors
Right-click a product card in your browser and select "Inspect". Identify the CSS classes wrapping your data.
- Card container:
<article class="product_pod"> - Title element:
<h3><a title="Book Name"> - Price element:
<p class="price_color"> - Link element:
<a href="...">
Send the Request and Parse the Page
Create a new file named scraper.py. We will ask the server for the page and convert the raw HTML into a searchable DOM object.
import requests
from bs4 import BeautifulSoup
import json
url = "https://books.toscrape.com/catalogue/category/books/science_22/index.html"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
else:
print(f"Failed to fetch page. Status: {response.status_code}")Extract Fields and Save as JSON
Find all product cards, loop through them, extract the text nodes, and store the output in a JSON file.
scraped_data = []
cards = soup.select("article.product_pod")
for card in cards:
title = card.select_one("h3 a")["title"]
price = card.select_one("p.price_color").text.strip()
link = card.select_one("h3 a")["href"]
scraped_data.append({
"title": title,
"price": price,
"url": f"https://books.toscrape.com/catalogue/category/books/science_22/{link}"
})
with open("science_books.json", "w", encoding="utf-8") as file:
json.dump(scraped_data, file, indent=4)
print(f"{len(scraped_data)} items scraped and saved to JSON.")This code works because it strictly follows the fundamental extraction pipeline. It sends the request, builds the DOM, targets the CSS selectors, and maps the unstructured text into a structured JSON object.
The Hidden API Shortcut Most Tutorials Skip
If the user's browser fetches data via a background JSON request, your Python script should fetch that exact same JSON request.
Parsing HTML is fragile. Bypassing the DOM to request the background JSON directly is faster, more reliable, and requires zero CSS selectors.
Find the JSON Request in DevTools
Navigate to your target website. Right-click anywhere, open "Inspect", and click the Network tab. Reload the page and filter by Fetch/XHR. Click through the listed requests and check the "Response" pane. You are searching for a clean list of objects matching the data visible on the screen.
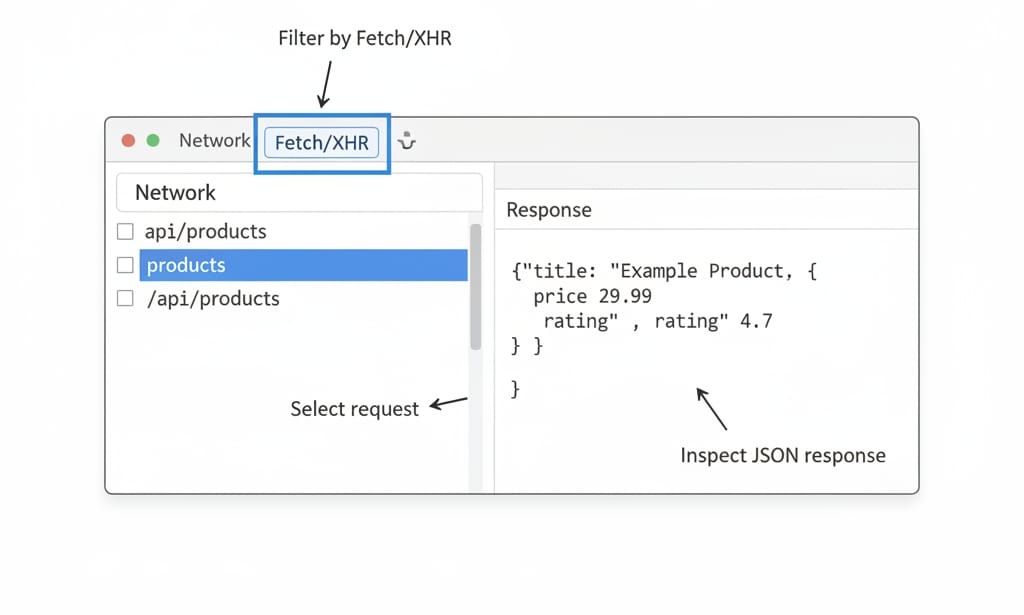
Recreate the Request in Python
Copy the endpoint URL. Your scraping script becomes incredibly simple.
import requests
api_url = "https://api.example.com/v1/products?category=shoes"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(api_url, headers=headers)
data = response.json()
print(data["products"][0]["title"])Parsing JSON removes fragility. You extract clean fields without regex cleanup and navigate pagination simply by changing a URL parameter like ?page=2.
What to Do When a Website Uses JavaScript
A JS-rendered page requires you to either intercept the background API or use a headless browser like Playwright to execute the code.
The most common failure for a beginner occurs when the page loads perfectly in the browser, but the script returns empty HTML.
If your selectors return None, right-click the page and select "View Page Source". If the source code lacks the visible data and instead shows an empty shell like <div id="app"></div>, the page uses Client-Side Rendering. The content appears only after the browser executes the JavaScript.
The requests library is an HTTP client, not a browser. It downloads the initial HTML file and stops. If there is no clean background API to intercept, you must use a headless browser. Playwright launches a real instance of Chromium, executes the JS, waits for the network to idle, and allows you to extract the fully rendered DOM.
Common Web Scraping Problems and Fixes
Scrapers are inherently brittle. Because you do not control the target website, your code will eventually break.
- Selectors return nothing: The website likely changed its CSS class names, or the element is rendered by JS. Print the raw HTML in your script to verify the element actually exists in the response.
- 403 Forbidden or 429 Too Many Requests: The server rejected your request. Slow down your extraction rate, add
time.sleep()between requests, and pass a standard browserUser-Agentin your request headers. - Pagination hides data: Your scraper only captured the first page. Find the "Next Page" button's
hrefattribute and loop your request, or inspect the Network tab for the JS-fed "load more" API parameters. - Messy or duplicated data: Normalize whitespace using
.strip()and deduplicate your final list based on unique product IDs.
From One Script to an Automated Scraping Pipeline
A script becomes a scalable scraping pipeline when you add persistent storage, retry logic, scheduling, and infrastructure management.
A script runs once on your laptop. A pipeline runs daily in the cloud, survives network errors, and feeds clean data to downstream applications.
Add Resilience and Scheduling
Production scrapers require robust logic. Add timestamps to every row to track data freshness. Wrap your HTTP requests in retry logic to handle temporary network blips. To schedule recurring runs, use cron on a Linux server for simple jobs, or orchestration tools like Airflow for complex workflows.
Leverage AI for Comprehension
The data extraction landscape is shifting. Recent benchmarks show that Large Language Models (LLMs) allow developers to bypass strict CSS selectors entirely. Open-source tools like Crawl4AI use AI models to comprehend and extract nested fields based on natural language prompts, solving the extraction fragility problem when layouts change.
Recent AI benchmarking shows end-to-end LLM agents can autonomously navigate and extract complex web data using just a single natural language prompt with minimal refinement (Source: Beyond BeautifulSoup, arXiv 2026).
Scale Seamlessly with Olostep
Managing custom Python scripts works beautifully for tens of pages. It becomes a nightmare when you need to scrape tens of thousands of dynamic pages daily. Managing proxy rotation, headless browser memory leaks, and broken custom parsers drains engineering time.
If you need rendering, crawling, and structured JSON output without stitching together multiple separate tools, Olostep is the right infrastructure layer. Olostep acts as an AI-first web data platform. Instead of fighting broken selectors, you interface with a unified API that discovers, extracts, and structures public web data reliably.
Is Web Scraping Legal?
Disclaimer: This is practical guidance, not legal advice.
Legal risk depends heavily on what data you extract, how you access it, and your jurisdiction. Web scraping public, non-personal factual data is generally legal. Scraping private data behind a login or extracting Personally Identifiable Information (PII) carries significant risk.
Before launching a scraper, confirm the data is public, avoid PII, and respect the server load by limiting your request rate. While a beginner scraping a practice site faces zero risk, commercial operations must stay vigilant. Always throttle your request speed to minimize server impact.
FAQ
What is a web scraper?
A web scraper is an automated tool that sends an HTTP request to a webpage, extracts specific structured data fields from the HTML or JSON response, and saves that data into a usable format.
Is web scraping legal?
Scraping public, non-personal factual data is generally legal. However, it depends on jurisdiction and access methods. Extracting private data behind a login carries significant legal risk.
How do beginners start web scraping?
Beginners should learn basic HTML and CSS selectors. Install Python, the requests library, and BeautifulSoup. Practice by sending a request to a static website and extracting text fields into a JSON file.
Do you need coding to scrape websites?
No. While Python provides the most flexibility, non-technical users can utilize no-code browser extensions or visual scraping software to extract structured data.
What programming language is best for scraping?
Python is the best language for web data extraction. It has the most robust ecosystem of libraries, including BeautifulSoup and Playwright, along with native integrations for data engineering pipelines.
Next Steps
You now possess the foundational workflow to build a web scraper. The key to mastering this skill is iteration.
- Inspect the source first: Always open the Network tab to check for hidden JSON APIs before writing HTML parsers.
- Start small: Use Python to target basic CSS selectors and output clean JSON data.
- Scale with intent: Escalate to browser automation, scheduling tools, or managed infrastructure like Olostep only when JavaScript rendering or scale demands it.
