

Python is the best language for web scraping overall, offering the most extensive ecosystem for data extraction, pipelines, and AI ingestion. Node.js is the best choice for automating browser-heavy, dynamic DOM interactions. Go (Golang) is the fastest language for high-throughput, concurrent crawling at scale. Java remains the optimal choice for large-scale enterprise JVM backend integrations.
Choosing the best programming language for scraping dictates your pipeline's speed, scalability, and maintenance overhead. The right choice depends entirely on your architectural constraints, target volume, and team fluency—not just generic popularity.
Market data validates focusing on these four core languages. According to the Apify 2026 infrastructure report, Python dominates the industry at 71.7%, followed by JavaScript at 17%. Other languages do not command enough market share to justify the ecosystem trade-offs for new scraping projects.
| Language | Best For | Avoid If | Key Tools |
|---|---|---|---|
| Python | Fast development, data pipelines, LLM/AI ingestion. | Your primary bottleneck is high-volume worker throughput. | Beautiful Soup, Scrapy, HTTPX, Playwright |
| Node.js (JS) | Browser-heavy scraping, JS-rendered sites, JS/TS teams. | Targets are mostly static HTML needing fast parse workflows. | Playwright, Puppeteer, Cheerio |
| Go | Recurring crawls, high-concurrency workers, lean deployments. | You need deep parsing libraries and fast iteration on logic. | Colly |
| Java | JVM-centric backends, enterprise services, typed platforms. | You need a fast prototype with minimal boilerplate code. | jsoup, Playwright for Java |
How to Choose a Web Scraping Language
Evaluate web scraping languages based on time to first working scraper, runtime efficiency under network load, ecosystem depth, and the ability to render dynamic JavaScript.
Prioritize Python for speed of development, Node.js for browser automation, Go for raw scale, and Java for enterprise integration. Let your team's existing technical fluency break any ties.
1. Ease of Use
Measure the time from concept to working scraper. Python and Node.js excel here due to minimal boilerplate. Fast debugging matters most for startup founders, growth engineers, and rapid validation loops.
2. Performance and Concurrency
Scraping is rarely CPU-bound; it is severely I/O-bound (network and memory). Efficient concurrency handling dictates real-world performance. Go’s Goroutines natively outperform standard threading models for massive parallel HTTP requests.
3. Ecosystem and Tooling
Look at the maturity of HTTP clients, parsers, and crawler frameworks. Modern Python scraping relies on asynchronous libraries like HTTPX with HTTP/2 support, leaving synchronous, stale requests setups behind.
4. JavaScript Handling
Handling dynamic single-page applications (SPAs) is a browser rendering problem, not a language limitation.
Because Playwright supports JS/TS, Python, Java, and .NET, automating React or Vue targets is no longer an exclusive Node.js capability.
Python vs JavaScript for Web Scraping
Python dominates general data extraction, ETL operations, and AI data pipelines. JavaScript (Node.js) wins when the browser itself is the primary workload, requiring heavy on-page DOM interactions.
Choose Python When:
- You prioritize data cleaning, Jupyter notebook iteration, and machine learning pipeline integration.
- You need a seamless growth path from a simple script to a robust crawler framework (Scrapy).
Choose Node.js When:
- Your extraction logic mirrors complex user interactions (clicking, waiting for DOM mutations, injecting scripts).
- Your engineering team already ships production backend code in TypeScript or JavaScript.
The Real Tiebreaker: Are you building a browser automation flow or a data pipeline? The Playwright API is nearly identical across languages. If you are extracting structured data for a database, lean Python. If you are reverse-engineering complex frontend states, lean Node.js.
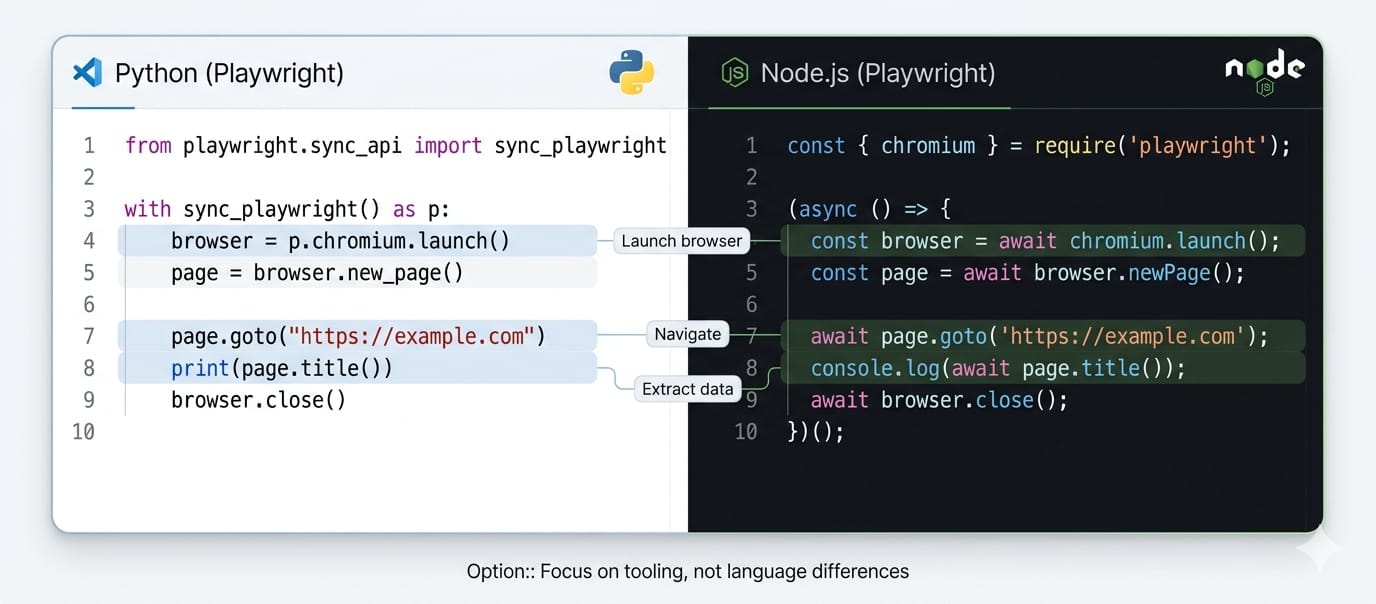
Python vs Go for Scraping at Scale
Go provides superior raw efficiency for high-throughput, highly concurrent crawling. Python offers faster iteration cycles for fragile parsing rules.
Choose Python When:
- Target site DOM structures change frequently, requiring the shortest possible feedback loop between a broken selector and a deployed fix.
- You are refining schemas and downstream transformations.
Choose Go When:
- The workload is stable, recurring, highly concurrent, and server-cost sensitive.
- You deploy distributed worker fleets and value the simplicity of a single compiled binary.
The Python GIL Reality in 2026
The outdated talking point claims Python cannot scale because of the Global Interpreter Lock (GIL). This is inaccurate for scraping workloads. Because scraping is network-bound, Python’s asyncio efficiently manages thousands of concurrent HTTP requests.
Furthermore, PEP 703 officially introduced an optional --disable-gil build.
Python 3.14, via PEP 779, officially supports free-threaded execution, unlocking true multi-core parallelism for CPU-heavy parsing tasks.
Prototype your extraction logic in Python. Only migrate hot paths to Go when server volume proves the explicit need.
Node.js vs Go
Choose Node.js When:
- 80% of your runtime lives inside a headless Chromium instance bypassing anti-bot challenges.
- The workload involves waiting for network idles and managing complex session cookies.
Choose Go When:
- You execute an HTTP fetch → parse → queue → store loop at massive volume.
- Your architecture functions as a distributed backend service rather than a scripted browser.
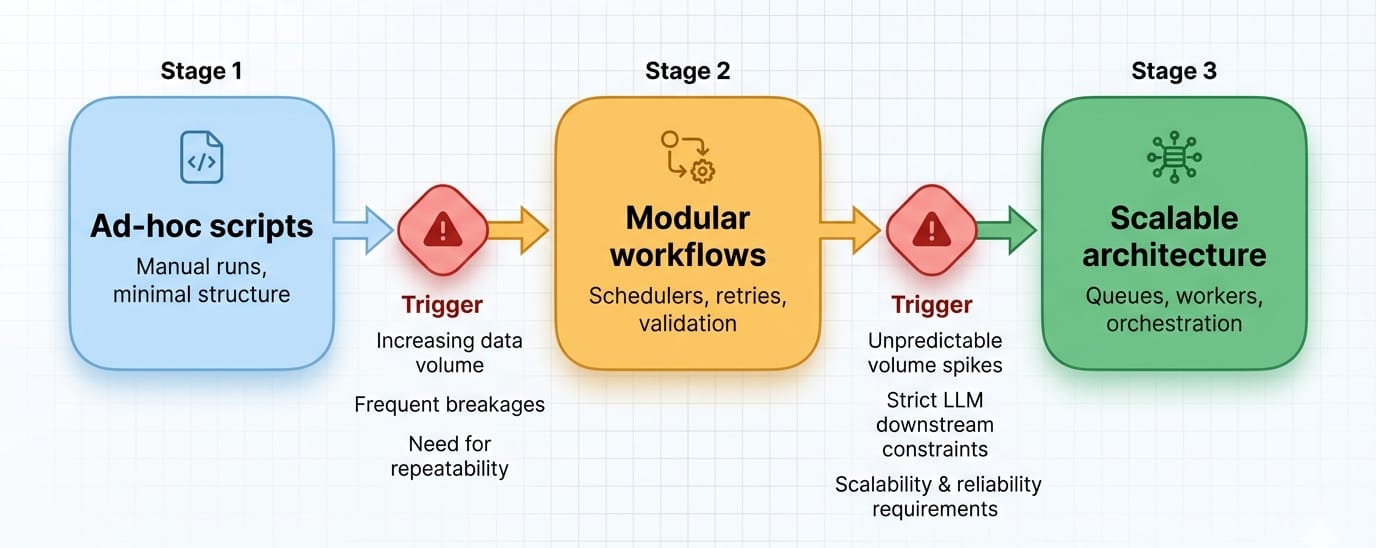
Scraping Maturity Levels: Scripts to Distributed Systems
Language choices evolve as your scraping operations scale.
Do not over-engineer early. Start with scripts (Python/Node.js) to validate extraction, move to frameworks for reliability, and only adopt distributed worker architectures (Go/Java) when scale demands it.
Stage 1: Scripts
Focus entirely on the speed of writing. Low overhead, fast execution. Engineers typically rely on Python (HTTPX + BeautifulSoup) or Node.js (Cheerio).
Stage 2: Frameworks
Focus on retries, proxy rotation, structured JSON output, and browser orchestration. Teams adopt Scrapy in Python or structured Playwright suites. Architecture and routing start to matter more than syntax.
Stage 3: Distributed Systems
Focus on concurrent workers, observability, and driving down the compute cost per crawl. This is the exact moment Go and Java become highly attractive.
Upgrade Triggers:
- Unpredictable network volume spikes.
- Moving from ad-hoc analysis to mission-critical daily crons.
- Strict downstream constraints (e.g., LLM ingestion requiring flawless structured JSON).
Why the Fastest Language is Not Always the Best
Go wins on raw benchmark speed, but the most efficient project is the one your team can ship, debug, and maintain without burning engineering hours on infrastructure.
Scraping code rarely bottlenecks at the CPU. Lifecycle delays happen while waiting on:
- Network latency and proxy rotations.
- Chromium rendering overhead.
- Rate limits, CAPTCHAs, and anti-bot HTTP 403 blocks.
- Constant maintenance after target sites change their layout.
Building a highly optimized Go architecture wastes resources if the target website forces you to rewrite your parser every three weeks. Apify’s 2026 infrastructure report highlights this reality: 62.5% of respondents saw infrastructure expenses rise, driven by anti-bot complexity and maintenance, not language inefficiency. Measure your actual pipeline bottlenecks before rewriting a working scraper.
Common Mistakes When Choosing a Scraping Language
| Mistake | Consequence | The Fix |
|---|---|---|
| Hype-driven adoption | Engineering spends weeks building in Go what Python handles in days. | Map the language to the project's maturity stage, not raw benchmarks. |
| Ignoring scalability early | A brittle script turns into an undocumented, failing daily cron job. | Implement retry logic, logging, and proxy management on day one. |
| Over-engineering | Building Kafka-backed distributed crawlers before securing a stable extraction schema. | Prototype extraction logic first. Scale the delivery queue second. |
| Optimizing parser speed blindly | Sub-millisecond DOM parsing means nothing if you receive instant HTTP 403 blocks. | Solve proxy routing, headers, and session fingerprints before optimizing parsers. |
When Language Matters Less Than Architecture
You transition from a language problem to a pipeline problem the moment you require deterministic structured JSON, delivery guarantees, scheduling, and outputs that plug directly into AI agents or vector databases.
Signs You Are Solving a Pipeline Problem
- You need perfectly structured JSON, not raw DOM fragments.
- You spend more time managing proxy pools and headless browsers than writing extraction rules.
- You require batch crawling, queueing, and webhooks.
The API-First Pipeline Path
For teams feeding LLMs, RAG systems, or data warehouses, you often do not need to choose a scraping language at all.
Welcome to the API-first data pipeline layer. Olostep replaces language-specific maintenance with a unified API that handles rendering, parsing, proxy rotation, and scheduling natively.
- Scrape: Execute real-time extraction returning Markdown, HTML, text, or structured JSON. It handles dynamic SPAs and complex page actions. Read the Scrape docs.
- Parsers: Transform messy web pages into backend-compatible JSON reliably for recurrent, scale-driven extraction. Read the Parsers docs.
- Batch Endpoint: Process up to 10k URLs per batch with a predictable 5–7 minute turnaround. Read the Batch docs.
- Crawl: Discover subpages, enforce depth limits, and trigger a
webhook_urlupon job completion. Read the Crawl docs. - Agents API: Automate complex research workflows on a schedule, routing output directly to JSON, CSV, or your database. Read the Agents docs.
Before committing engineering resources to rewrite for scale, test an API-first workflow. It is the fastest way to determine whether your bottleneck requires a language switch or a pipeline upgrade.
The Final Decision Framework
| Your Situation | Best Pick | Why It Wins |
|---|---|---|
| Need a safe default & AI data | Python | Shortest path from idea to structured data pipelines. |
| Browser-heavy / Team knows JS | Node.js | Native alignment with browser automation and SPA rendering. |
| Scale pain / High concurrency | Go | Exceptional operational efficiency, low memory footprint. |
| Existing enterprise backend | Java | Clean integration with heavy JVM data stacks. |
| Need structured data at scale | API-first pipeline | Eliminates proxy, infrastructure, and parser maintenance completely. |
Select the best language for web scraping based on your current operational stage, then re-evaluate after 30 days of real-world network load.
FAQ
Which language is best for web scraping?
Python is the best programming language for scraping due to its rich ecosystem of data extraction tools like Scrapy and Beautiful Soup. However, Node.js is better for scraping dynamic JavaScript-heavy websites, while Go is the fastest language for handling massive, highly concurrent crawling operations.
Is Python better than JavaScript for scraping?
Python is better for backend data pipelines, ETL processes, and AI model ingestion because of its powerful data processing libraries. JavaScript (Node.js) is better when your target websites heavily rely on complex client-side rendering or when you need deep, native browser automation.
What is the fastest language for web scraping?
Go (Golang) is the fastest language for web scraping. It offers superior raw execution speed, a minimal memory footprint, and highly efficient network concurrency through Goroutines, making it ideal for large-scale distributed web crawlers processing millions of requests.
Can you scrape websites with JavaScript?
Yes, you can easily scrape websites using server-side JavaScript via Node.js. Modern browser automation tools like Puppeteer and Playwright natively support JS/TS, making it a standard, highly supported path for extracting data from dynamic, JavaScript-rendered websites.
What language do hackers use for scraping?
Hackers and security researchers commonly use Python, Go, and Bash for automated scraping due to their fast execution and extensive native networking libraries. For legitimate web data extraction, your choice should depend entirely on workload scale, data pipeline requirements, and team fluency.
